Blockchain 101: Consenso en Polkadot
Este artículo es parte de una serie más larga sobre Blockchain. Si este es el primer artículo que encuentras, te recomiendo comenzar desde el inicio de la serie.
El episodio anterior fue algo así como un calentamiento, para que pudiéramos empezar a sumergirnos en el (profundo) mundo de Polkadot.
Hasta ahora, hemos estado hablando de Rollups (o Parachains), pero dijimos que estos carecen de una funcionalidad crucial que esperaríamos de cualquier Blockchain: consenso. Esto es intencional, ya que el consenso se delega a una cadena padre, llamada Relay chain.
Así que hoy, comenzaremos a hablar de este componente muy central en la infraestructura de Polkadot, y su rol como el núcleo mismo de esta tecnología.
¡Vamos!
Consenso
Del artículo anterior, sabemos que cada Rollup tiene la capacidad de definir sus propias reglas de transición de estado, pero por sí solos no pueden hacer crecer sus propias Blockchains (Rollups). Claro, recibirán transacciones, e incluso propondrán bloques, pero el consenso será delegado a la Relay chain.
Así que de entrada, parece que estamos en un aprieto: ¿cómo puede la Relay chain verificar las transiciones de estado de los Rollups?
¡Y necesita hacerlo para proporcionar consenso, porque necesita asegurar que la evolución de un Rollup siga sus propias reglas!
Nuestro primer instinto debería ser que la Relay chain debe tener algún tipo de conocimiento de todos los Runtimes existentes. Y eso es exactamente correcto: los Runtimes deben estar registrados en la Relay chain para que todo este mecanismo funcione.
Pero entonces... Si los Runtimes también se almacenan en la Relay chain, ¿cómo son diferentes de los Contratos Inteligentes? ¡Parece que vamos exactamente en la dirección que nos propusimos evitar!

¿Entonces?
Collators
La diferencia clave radica en dónde vive el estado. Cada Rollup mantiene un registro de su propio estado (y Runtime), así que veamos qué pasa desde su perspectiva.
¿Cómo funcionaría la producción de bloques en un Rollup? Bueno, algún tipo de validador (o al menos productor de bloques) necesitaría producir un bloque con transacciones válidas, y luego de alguna manera necesitaría decirle a la Relay chain algo como:
Aquí tienes un bloque — necesito que lo valides, y me digas una vez que esté bien para que lo agregue a mi Blockchain
Este es el asunto: la Relay chain no sabe mucho sobre el estado de los Rollup. Nuestro productor, sin embargo, sí tiene esta información. Así que con algo de magia criptográfica, lo que hacen es proporcionar la información suficiente para que la Relay chain haga su trabajo.
Los nodos encargados de producir bloques y proporcionar esta información se llaman Collators, y la información que proporcionan es una prueba corta llamada Prueba de Validez (PoV por sus siglas en inglés).
Pero ¿qué contienen exactamente estas pruebas cortas?
Construyendo las Pruebas
En teoría, hay varias formas de probar que una computación fue ejecutada correctamente. Porque eso es lo que estamos haciendo: el Runtime en realidad no es más que una función, que toma un estado actual y una transacción (también llamada extrinsic en la jerga de Polkadot), y produce un nuevo estado. Así:
Donde representa el estado, y representa una transacción. ¡Y la función es el Runtime!
Tal función usualmente se llama función de transición de estado.
Así que sí, nuestro objetivo puede ser reformulado como probar que la salida de la función fue correctamente computada para un conjunto dado de entradas.
Hay varios sistemas de prueba que nos permiten hacer tal cosa, como por ejemplo:
- Pruebas de conocimiento cero (como SNARKs o STARKs) prueban la corrección de una computación, opcionalmente sin revelar cierta información.
- Pruebas de fraude, que asumen que la computación es correcta a menos que alguien pueda probar lo contrario.
- Pruebas basadas en testigos, que proporcionan justo los datos suficientes para que alguien más verifique la computación.
Polkadot opta por el tercer enfoque: pruebas basadas en testigos, construidas a partir de árboles de Merkle.
La razón para esto es que el estado del Rollup, de manera muy similar a Ethereum, se almacena como un trie de Merkle Patricia modificado.
Para tener una referencia, mirá aquí.
La idea principal es bastante simple, en realidad: compartir solo las partes que han cambiado, más información suficiente para reconstruir la raíz del estado. Sí... Tal vez un ejemplo sea de ayuda.
Digamos que Alicia quiere transferir algunos tokens a Beto. La consecuencia de esta acción es que sus balances cambien — pero el resto del estado está prácticamente intacto. Ahora, sus balances representarán cada uno una sola hoja en el trie — algo así:
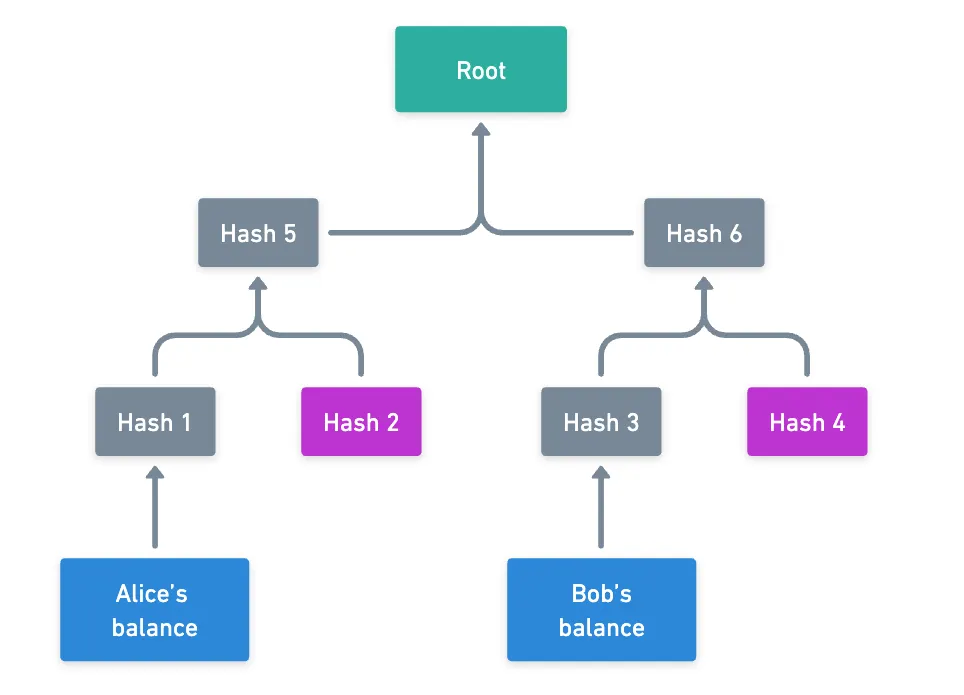
Esta es por supuesto una vista condensada del trie completo: los hashes en púrpura pueden ocultar subtries largos. Esa es exactamente la belleza de esta estructura de datos: solo necesitas unos pocos hashes intermedios para reconstruir la raíz del estado (que es una huella digital de todo el trie) a partir de los balances de Alicia y Beto.
Concedido, normalmente necesitas algunos más de los hashes púrpura, ya que en realidad estamos trabajando con un trie radix-16.
Al cambiar los balances objetivo, esta es la nueva situación:
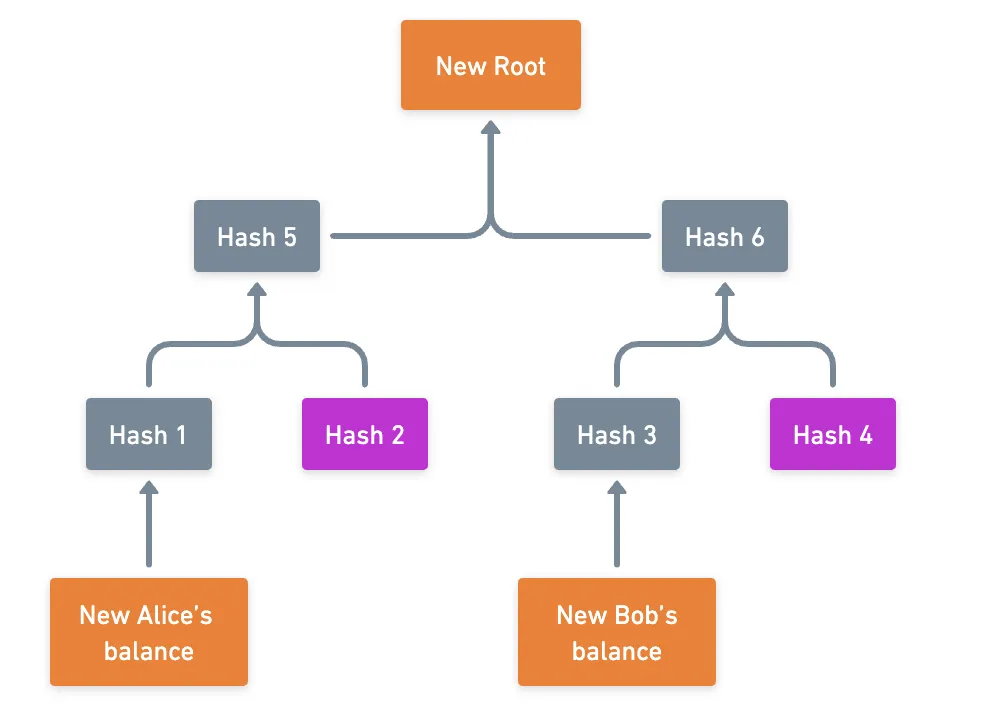
¡Así que teniendo solo el trie condensado de antes, y los balances actualizados y la nueva raíz, tenemos todo lo que necesitamos para verificar la transición de estado!
Para completar esto, decimos que estas Pruebas de Validez son solo pruebas basadas en testigos del estado de los Rollups.
Con esto, hemos terminado principalmente con el rol de los Collators en esta historia. Nuestra próxima parada será entender cómo la Relay chain toma estas PoVs, y las valida. Aquí, el desafío es hacer esto eficientemente, ya que nuestra capa base tendrá que trabajar a través de la validación de varios Runtimes diferentes.
En lugar de pensar en términos de "la Relay chain" validando estos bloques, será útil abordar esta próxima sección en términos de actores individuales, y el proceso general que ocurre inmediatamente después de la presentación de estos bloques — un protocolo conocido como ELVES.
Dato curioso: el paper original dice que ELVES significa Endorsing Light Validity Evaluator System, mientras que la documentación oficial establece que significa Economic Last Validation Enforcement System.
¡Supongo que puedes decidir cuál es más adecuado después de verlo en acción!
Protocolo ELVES
Los protocolos de consenso en general tienen solo unos pocos objetivos, entre los cuales están asegurar que exista una sola historia compartida, y que cada paso (bloque) en esa historia sea válido.
Por el contrario, esto significa que los bloques inválidos nunca deberían ser aceptados — deberían ser descartados después del examen por los validadores de la Relay chain. Pero ¿cuántos validadores deberían realizar esta auditoría? ¿Cuántos son suficientemente seguros?
En términos generales, no podemos hacer que cada nodo validador verifique cada bloque de Rollup, ya que eso haría que el escalado fuera casi imposible.
Esta es una realidad que enfrentan la mayoría de las Blockchains, y la razón por la que necesitamos mecanismos de consenso sofisticados.
Polkadot resuelve esto a través de ELVES, que está compuesto por un total de cuatro fases o pasos.
Backing
El primer paso se llama backing.
Cuando un Collator presenta un bloque de Rollup (junto con su PoV), un pequeño grupo de validadores de la Relay chain (llamados backers) que están específicamente asignados a ese Rollup reciben el bloque, y realizan una validación inicial.
Los Backers esencialmente hacen el trabajo pesado: ejecutan la función de transición de estado del Rollup (Runtime), y verifican que la PoV sea correcta.
Si todo está bien, dan fe de esto a través de lo que se llama un candidate receipt, poniendo su sello de aprobación en este nuevo bloque.
Ellos respaldan (backean) la validez del nuevo bloque. ¡De ahí el nombre!
Disponibilidad
La segunda fase se llama la fase de disponibilidad.
Los Backers afirman que el nuevo bloque es válido... ¿Pero podemos confiar en ellos? ¡Podrían haber evaluado incorrectamente la validez del bloque, o incluso estar mintiendo! ¿Cómo podemos asegurar que este no sea el caso?
Simple: hacer que otros validadores hagan una segunda ronda de validación de bloques.
Para esto, los backers necesitan hacer el bloque disponible a sus pares. Por fácil que esto suene, hay un par de problemas asociados sobre cómo distribuimos estos bloques:
- Si los backers envían cada bloque a cada otro par, pronto los nodos tendrían que almacenar muchos bloques en memoria, la mayoría de los cuales nunca verificarán. ¡No es ideal!
- Si los backers esperan a que lleguen desafíos antes de distribuir el bloque, la latencia general del proceso se incrementaría, ralentizando el consenso. Tampoco es ideal.
¿Qué tal una solución intermedia entonces? Afortunadamente, tal cosa existe en la forma de una técnica llamada codificación de borrado.
¡He hablado de esto extensivamente en un post anterior, así que ve a verlo si quieres una explicación completa!
Va así: el bloque se divide en chunks, y solo una pequeña porción de estos chunks se distribuye por adelantado a otros nodos. Cuando un par quiere examinar el bloque, puede pedir a los pares otros chunks pequeños, y reconstruir el bloque original. Curiosamente, no necesitan todas las piezas — solo una fracción será suficiente.
¡Esto es genial porque las comunicaciones son ligeras, y los nodos no necesitan almacenar tanta información!
Y realmente, la distribución ocurre junto con la fase de backing, no puramente en secuencia.
Una vez que suficientes validadores dan fe de haber recibido sus respectivos chunks, entonces el protocolo pasa a la siguiente fase.
Aprobación
Ahora viene la parte más interesante del protocolo (en mi opinión): la fase de aprobaciones, que es donde ocurre la segunda ronda de revisión.
El protocolo selecciona aleatoriamente un pequeño comité de validadores para auditar los bloques respaldados. Importante, el comité se elige después de que el bloque ha sido distribuido en la fase anterior. Y la selección aleatoria es impulsada por Funciones Aleatorias Verificables (VRFs).
¿Por qué es esto importante? ¡Porque si los backers supieran quién sería parte del comité por adelantado, podrían coaccionarlos para que aprueben el bloque!
¡Al hacer las cosas en este orden, hacemos difícil que los nodos deshonestos se entreguen a comportamientos corruptos!
Si todos los miembros del comité aprueban un bloque, entonces es aceptado, y el Rollup puede adjuntarlo a su cadena. Pero algunos auditores pueden afirmar que un bloque es inválido, o pueden no responder a tiempo (llamados no-shows). En este escenario, se necesita otro paso.
Escalación y Disputas
Los no-shows son simples de manejar: ELVES selecciona validadores aleatorios adicionales para proporcionar sus aprobaciones.
Esto es bastante inteligente, en realidad: si los no-shows ocurren debido a que los validadores están siendo atacados, ¡entonces el comité sigue creciendo hasta que el atacante no puede realísticamente seguir el ritmo!
Sin embargo, cuando un auditor afirma que un bloque es inválido, el sistema entra en una fase de disputa: la decisión de aprobar un bloque se escala inmediatamente a todos los validadores, y cada uno necesita verificar el bloque y votar.
Para asegurar que los validadores voten "correctamente", el protocolo castiga al lado minoritario (sí, este es un protocolo de Proof of Stake). Imponemos consecuencias serias por mal comportamiento, lo que añade a la seguridad del modelo. Y en general, tratar de corromper este sistema es bastante complicado, porque tendrías que:
- Corromper los validadores de backing iniciales
- Tener suficientes recursos para crashear auditores honestos mientras son seleccionados aleatoriamente
- ¡Y arriesgar castigo masivo si son atrapados!
Y durante la operación "normal" — ya sabes, bloques válidos siendo producidos, y nodos estando disponibles para realizar sus deberes — solo una pequeña fracción de validadores están verificando activamente cualquier bloque de Rollup en particular.
En otras palabras, ¡este protocolo está muy bien adaptado para la paralelización en la ejecución del mecanismo de consenso!
Interoperabilidad
¡Bien! Hemos cubierto cómo los Rollups producen bloques, y cómo la Relay chain los valida a través de ELVES.
Ahora solo nos falta una última pieza de la arquitectura de Polkadot: ¿cómo se comunican realmente estos diferentes Rollups entre sí?
El Desafío de la Interoperabilidad
Ya sabemos que la mayoría de las Blockchains existen en aislamiento.
Mover activos de una Blockchain a otra Blockchain típicamente requiere puentes — sistemas que simplemente mantienen tus activos en una cadena mientras acuñan representaciones equivalentes en otra.
Crucialmente, estos sistemas usualmente están centralizados. Como tal, frecuentemente son el eslabón más débil en las operaciones entre cadenas. Hay un dicho que ya he mencionado antes cuando hablaba de criptografía:
Una cadena no es más fuerte que su eslabón más débil.
Y así, estos puentes a menudo se convierten en objetivos de ataques.
Por supuesto, todo esto surge de la simple razón de que la interoperabilidad no fue considerada como parte del diseño inicial de muchos sistemas, porque nadie tenía una bola de cristal.

De manera similar al artículo anterior, imaginemos por un momento que estamos a punto de construir una nueva Blockchain con soporte para interoperabilidad nativa entre Rollups, sin depender de puentes centralizados. ¿Cómo funcionaría eso siquiera?
Digamos que Alicia quiere enviar 100 tokens almacenados en su cuenta en el Rollup , a la cuenta de Beto en el Rollup . Esto debería ser simple: el Rollup quema los 100 tokens de Alicia, y el Rollup mintea 100 tokens equivalentes para Beto.
Pan comido, ¿verdad?
No exactamente. Imagina que el Rollup exitosamente quema los tokens, pero entonces el Rollup falla en acuñarlos. Alicia pierde sus tokens, y Beto no obtiene nada. Alternativamente, si el Rollup acuña los tokens pero el Rollup falla en quemarlos, bueno... Ahora hemos esencialmente duplicado los tokens. Por supuesto, ambas situaciones son alarmantes, y deberían evitarse a toda costa.
Para resolver esto, ambos Rollups necesitarían de alguna manera coordinar una transacción compleja de dos fases.
Como un commit de base de datos distribuida.
El Rollup necesitaría prepararse para quemar los tokens, el Rollup necesitaría prepararse para acuñarlos, y solo cuando ambos estén listos ejecutarían realmente las operaciones.
Aunque esto añade complejidad (y latencia) al sistema, es al menos teóricamente posible. Sin embargo, esto requiere algún tipo de mecanismo para comunicación directa entre los Rollups.
Mientras añadimos más Rollups al ecosistema, debemos asegurar que la comunicación entre estos sistemas separados aún funcione. Si cada Rollup tiene sus propios formatos y peculiaridades, entonces el caos se desataría realmente rápido.
Es casi evidente que se necesita algún tipo de estándar.
Polkadot trató de aprender de esto, y se le ocurrió su propia solución: un mecanismo de comunicación entre cadenas nativo, en la forma de XCM.
XCM
El formato de Cross-Consensus Messaging (o XCM por sus siglas en inglés) es simplemente eso: un formato de mensajería.
Aunque "simplemente" es una subestimación de su elegancia. XCM es más como un lenguaje universal que describe acciones. Y en lugar de que los Rollups traten de coordinar transacciones complejas directamente, XCM toma un enfoque diferente: crea una forma estándar de describir intenciones, lo que habilita dos cosas:
- permite que la Relay chain maneje la coordinación.
- permite que cada Rollup implemente la lógica para manejar el mensaje.
Para poner esto en perspectiva, revisitemos el ejemplo anterior. Alicia quiere enviar 100 tokens del Rollup , a la cuenta de Beto en el Rollup . Así que el mensaje XCM diría algo así:
Retira 100 tokens de la cuenta de Alicia, teletranspórtalos al Rollup , y deposítalos en la cuenta de Beto.
El mensaje describe perfectamente lo que debería pasar, pero no cómo debería pasar. Cada Rollup interpreta estas instrucciones de acuerdo a sus propias reglas y capacidades. Pero eso plantea la pregunta: ¿cómo nos aseguramos de que el Rollup realmente ejecute el mensaje?
Ejecución de Mensajes
La respuesta es tal vez más matizada de lo que esperarías.
XCM sigue un modelo de disparar y olvidar — cuando el Rollup envía un mensaje, no obtiene confirmación de que el Rollup lo ejecutó. Pero tomemos un momento para analizar el ciclo de vida de un mensaje, y veamos qué podemos aprender de eso:
- Primero, el Rollup crea el mensaje XCM y lo envía "arriba" a la Relay chain.
- La Relay chain entonces almacena el mensaje en su propio almacenamiento, y también lo enruta a una cola de mensajes en el Rollup .
- Cuando los Collators del Rollup construyen su próximo bloque, se espera que procesen los mensajes en sus respectivas colas.
- Los validadores de la Relay chain verifican que los bloques recién producidos sean válidos, basándose en el procesamiento de los mensajes recibidos.
Nota que este mecanismo, llamado Horizontal Relay-routed Message Passing (HRMP), se espera que sea reemplazado por el protocolo más ligero Cross-Chain Message Passing (XCMP).
La diferencia clave es que, en la actualidad, todos los mensajes se almacenan en la Relay chain. XCMP apunta a almacenar mensajes directamente en los Rollups, y mantener la información almacenada en la Relay chain muy ligera.
Bien, así que hay algunas cosas que decir aquí. Primero y más obvio, no hay garantía absoluta de que cada mensaje será procesado por el Rollup objetivo.
Pero no todo está perdido — tanto en HRMP como en XCMP, la Relay chain mantiene información sobre qué mensajes XCM cada Rollup debería ejecutar, en la forma de colas de mensajes. Gracias a esto, los validadores de la Relay chain tienen suficiente contexto para verificar (y verificarán) que los Collators están efectivamente procesando mensajes, y en el orden esperado. Si no lo hacen, entonces sus bloques eventualmente no serán considerados válidos, y su producción de bloques será detenida.
¿Qué pasa con las ejecuciones fallidas? Bueno, XCM incluye mecanismos como asset trapping — los activos no simplemente desaparecen, se atrapan y pueden ser recuperados más tarde a través de procesos separados. Naturalmente, hay más complejidad alrededor de esto, ya que los mensajes XCM pueden ser usados para representar todo tipo de acciones, no solo transferencias de tokens.
En general, XCM es un paso en la dirección correcta. Tiene un potencial enorme, pero su éxito depende de cómo se use e implemente.
¡Supongo que tendremos que esperar y ver!
Resumen
¡Hemos cubierto mucho terreno hoy! Recapitulemos rápidamente:
- Vimos cómo los Collators son nodos especializados que producen no solo bloques, sino pruebas cortas de la validez de su transición de estado, en la forma de Pruebas de Validez.
- Estos bloques son entonces auditados por el protocolo de consenso ELVES, que brilla por su escalabilidad, eficiencia y seguridad.
- Finalmente, XCM habilita interoperabilidad nativa entre rollups. Ya ve mucho uso en el ecosistema de Polkadot, y permite interacciones muy ricas.
Claro, no hemos cubierto todo (por ejemplo, no mencioné async backing, que es una característica bastante interesante en sí misma) — pero esto debería ser más que suficiente para tener una buena comprensión de cómo opera el consenso en Polkadot.
Como ejercicio adicional, podemos tomar nuestro conocimiento recién adquirido y tratar de usarlo para entender una de esas imágenes circulando por internet sobre la arquitectura de Polkadot. Veamos si podemos identificar todos los componentes:

Cada una de esas pequeñas cosas "acoplándose" al círculo es un grupo de collators (los puntos rosados), que producen bloques para una parachain (el cuadrado gris), y están respaldados por algunos validadores (esas figuras rosadas largas y redondeadas).
La relay chain es el gran círculo gris en el medio, y las conexiones rosadas que se enhebran dentro de él son los mensajes XCM. Por último, los "pools" de validadores que parecen enlazarse a múltiples collators probablemente están relacionados con on-demand coretime — un concepto que pronto exploraremos.
Lo que hace a Polkadot bastante único no es solo una sola innovación, sino más bien cómo estas diferentes piezas trabajan juntas. Realmente es uno de los pocos ejemplos que me destacan como un intento de construir más que solo una Blockchain, sino infraestructura sólida para un ecosistema de Blockchains interconectadas.
¡Por supuesto, el otro gran candidato es el ecosistema de Ethereum, que revisitaremos antes de que termine esta serie!
El tiempo dirá qué tan exitosa se vuelve esta visión. Si algo, las increíbles innovaciones técnicas que hemos discutido empujan a toda la industria hacia adelante, y definitivamente vale la pena aprender sobre ellas.
Hablando de innovaciones técnicas, Polkadot aún tiene algunas sorpresas bajo la manga. Por una parte, no hemos respondido cómo los Rollups obtienen acceso al poder de validación de la Relay chain. Quiero decir, los validadores no deberían trabajar gratis, así que debe haber algún tipo de incentivo en su lugar, ¿verdad?
No quiero arruinar la acción aquí, ¡así que tendrás que esperar al próximo artículo para encontrar la respuesta!
¡Nos vemos entonces!


¿Te resultó útil este contenido?
Apoya a Frank Mangone enviando un café. Todos los ingresos van directamente al autor.