Blockchain 101: Almacenamiento
Este artículo es parte de una serie más larga sobre Blockchain. Si este es el primer artículo que encuentras, te recomiendo comenzar por el inicio de la serie.
La última vez, hicimos una introducción de alto nivel a Ethereum.
Aunque muchas de las ideas que discutimos eran nuevas en comparación con Bitcoin, en realidad son bastante fundamentales en la mayoría de los sistemas Blockchain — especialmente la capacidad de crear y ejecutar estos programas que llamamos Contratos Inteligentes.
El nivel de abstracción que hemos manejado hasta ahora oculta todo el funcionamiento interno de la arquitectura de Ethereum. Y eso está bien como primer acercamiento, ya que algunos conceptos se sienten muy nuevos y exóticos, de nuevo, en comparación con Bitcoin.
Pero tú y yo sabemos — no estás aquí por el nivel más alto de abstracción.
En los próximos artículos, nos sumergiremos en la maquinaria de Ethereum, descubriendo lentamente sus secretos.
Para empezar, veamos cómo se almacenan los datos.
¿Comenzamos?
Estado y Almacenamiento
Lo primero que necesitamos entender es cómo se modela el estado de la Blockchain en Ethereum, para que podamos descubrir estrategias para almacenarlo. En este aspecto, Bitcoin era mucho más simple: el estado era solo una lista de UTXOs disponibles.
Aunque almacenar estos UTXOs tiene sus vueltas, conceptualmente es bastante simple. Podríamos imaginar esto como una tabla que contiene el estado completo, así:
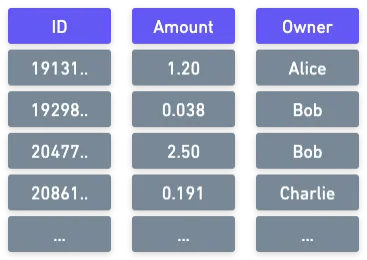
Entonces, ¿qué hay de Ethereum? Claramente no va a ser tan simple. El estado es un concepto abstracto para representar prácticamente cualquier cosa. Necesitaremos algo un poco más sofisticado que nuestra simple tabla conceptual...
Ya que sabemos que estamos trabajando con cuentas, y básicamente la totalidad del estado de Ethereum puede describirse en términos del estado de cuentas individuales, preguntémonos: ¿qué define exactamente el estado de una cuenta?
En el artículo anterior, mencionamos un par de cosas importantes:
- Las cuentas pueden tener un balance en el token nativo (Ether)
- Las cuentas pueden ser una Cuenta de Propiedad Externa (EOA), o una cuenta de contrato, conteniendo código para ejecutar
Además, hay un par de elementos más que necesitamos agregar a la mezcla. Una de esas cosas es un nonce, que es un contador incremental de transacciones. También necesitamos otra cosa que discutiremos en un momento.
Podemos pensar en las cuentas como contenedores de información de la cuenta, en forma de un conjunto de pares clave-valor:
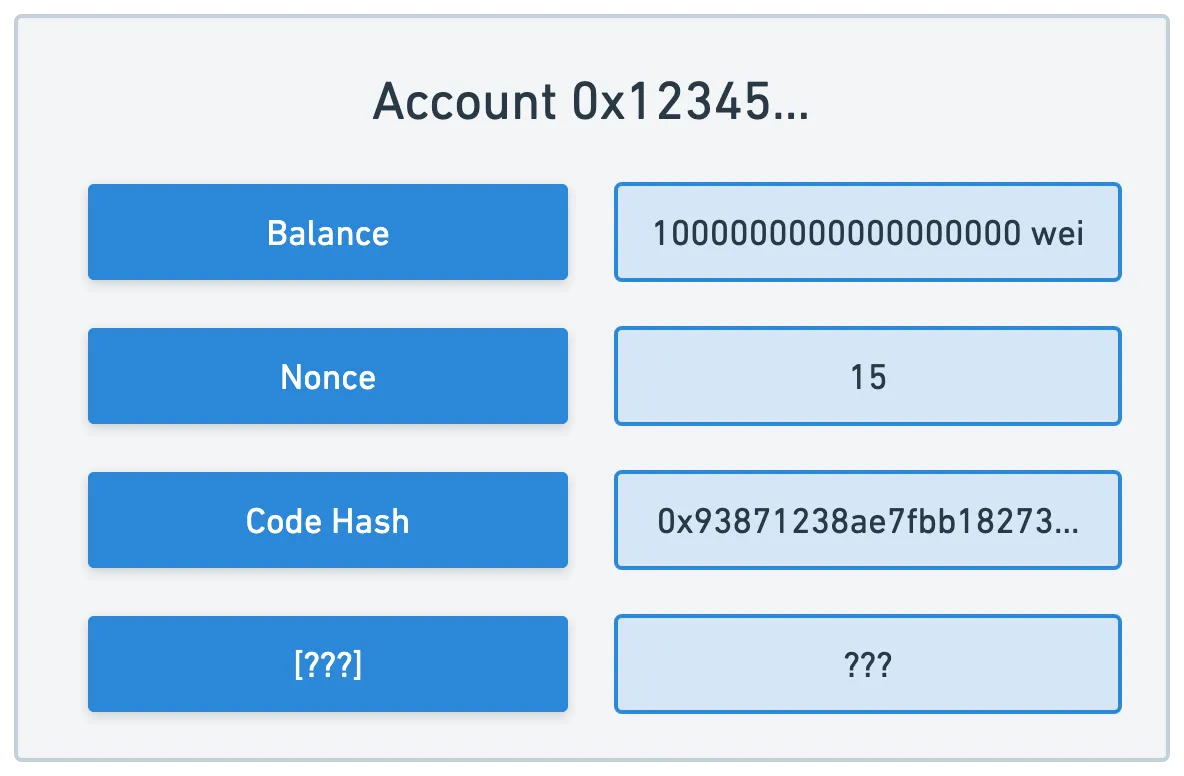
Ahora, una cosa que es deseable (aunque no hablamos mucho de esto en nuestro paso por Bitcoin) es tener algún tipo de huella digital para todo el estado de la Blockchain, de modo que podamos identificar un estado mediante un único valor, y estar seguros de que si algo cambia, esta huella digital cambiará.
Esta es una forma útil de etiquetar o identificar el estado actual de la Blockchain.
Ya conocemos una estructura que permite este tipo de proceso de digestión en una única raíz: ¡los árboles de Merkle!
Pero los árboles de Merkle por sí solos simplemente no serán suficientes en este escenario. En particular, tienen dos limitaciones importantes:
- No son muy prácticos para operaciones de inserción (ni eliminación), ya que necesitamos ocuparnos del relleno (asegurarnos de que el número de hojas sea una potencia de ), y
- No ofrecen ninguna manera de buscar nodos, ya que no hay un sistema de identificación incorporado
Creo que el segundo punto es el más importante aquí: dada la dirección de una cuenta, queremos poder encontrar rápidamente sus atributos.
Para abordar estos problemas, se utiliza una estructura de datos ligeramente diferente para codificar las cuentas: un trie de Merkle-Patricia.

Encontrando una Estructura de Datos Adecuada
Lo que necesitamos es una estructura que permita algún tipo de indexación. Los árboles de Merkle tienen índices incrementales muy simples — estos valores solo se usan para mantener las hojas ordenadas, pero no dicen nada sobre su contenido.
Pero hay otra estructura que pone el identificador de un nodo en el centro de su diseño: un trie.
Los tries (también conocidos como árboles de prefijos) son, como esperarías por el nombre, tipos especiales de árboles. Comenzando desde el nodo raíz, cada hoja está asociada a un carácter alfanumérico. Debido a esto, seguir cualquier camino en el árbol formará una cadena de caracteres, un nodo a la vez.
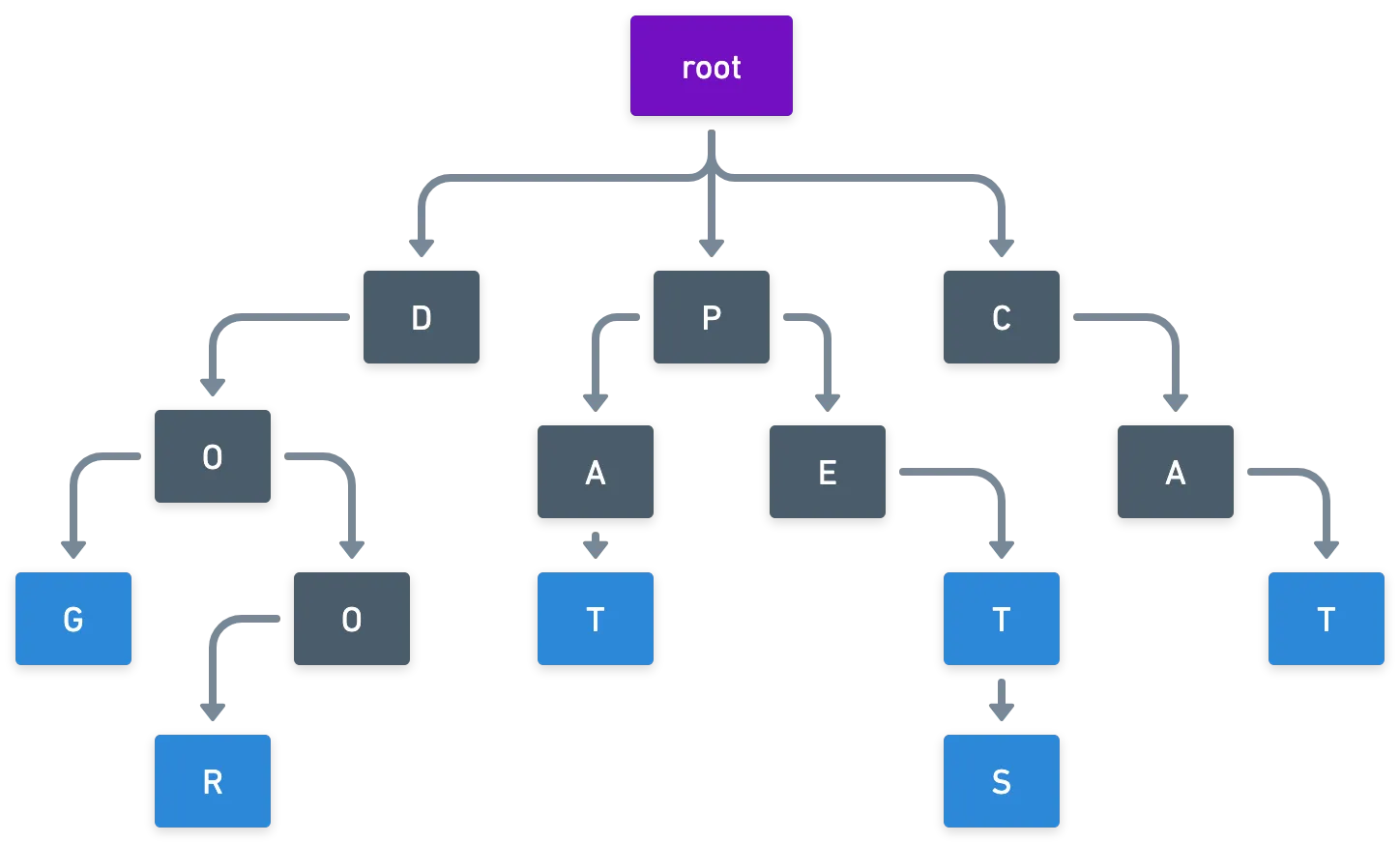
La parte genial de este tipo de estructura es que encontrar un nodo por su índice es tan simple como atravesar el árbol una letra (nodo) a la vez.
Y por supuesto, un nodo terminal contendrá la información almacenada bajo el índice especificado.
Algo que sucede con estos árboles es que su profundidad está determinada por el índice más largo, en términos de longitud de caracteres. Y esto puede causar problemas de almacenamiento, porque necesitamos mantener un registro de una gran cantidad de nodos intermedios en memoria. Además, los nodos pueden tener potencialmente un solo hijo, lo que nos plantearía un problema, por razones que veremos más adelante.
Para intentar remediar estas situaciones, podemos usar una variación simple: un árbol radix. Esencialmente, condensamos los nodos que tienen un solo hijo en un nodo.
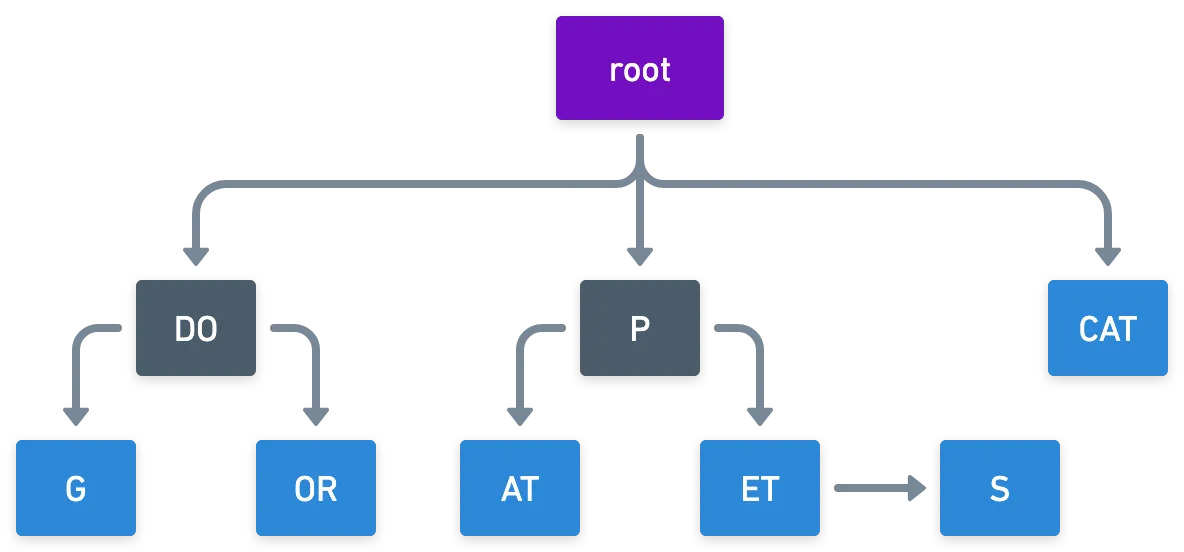
Puedes ver las inserciones y eliminaciones en acción en este sitio web.
Una cosa a notar es que hay un número máximo de hijos que un nodo puede tener. En el caso de caracteres alfanuméricos, un solo nodo puede tener hasta hijos diferentes, uno para cada carácter único. No es sorprendente que este número se llame el radix del trie — que está determinado por el "alfabeto" que usamos, y no por la estructura en sí.
Patricia Tries
Todo esto para finalmente decir:
Los tries Patricia son esencialmente tries radix con radix = 2, con algunos ajustes
Solo por completitud: PATRICIA significa "Practical Algorithm To Retrieve Information Coded in Alphanumeric" (Algoritmo Práctico Para Recuperar Información Codificada en Alfanumérico).
Esto significa que el alfabeto es binario — solo se usan los números y .
Hay otras sutilezas a considerar al construir un trie Patricia, una de las cuales es la inclusión de un valor de salto que hace las travesías más eficientes.
Por último (e importante), los Patricia tries pueden organizarse de tal manera que no haya nodos con un solo hijo. En otras palabras, cada nodo será o bien un nodo hoja (sin hijos) o un nodo interno (dos hijos).
Si bien los radix tries en general pueden tener nodos con un solo hijo, es posible imponer esta condición de "ningun nodo con un solo hijo" en cualquier radix trie.
Aquí hay un ejemplo:
Supongamos que queremos organizar estas claves en un Patricia trie
- 10010000 (144)
- 10010100 (148)
- 10011000 (152)
- 10100000 (160)
- 11000000 (192)
- 11000001 (193)
Así es como podría verse un trie Patricia:
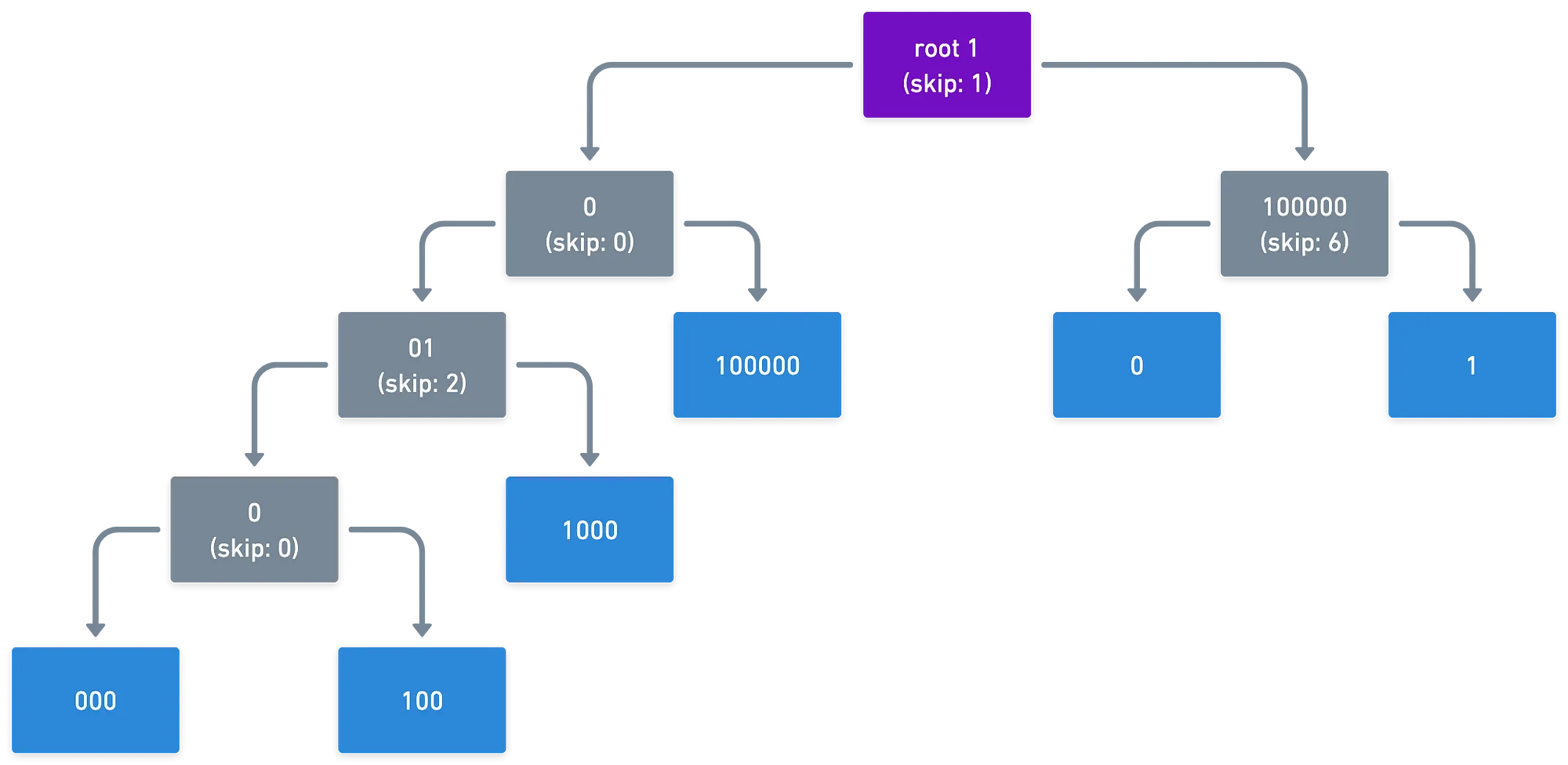
Los Patricia tries son muy compactos y eficientes en memoria, mientras que también permiten inserciones y eliminaciones rápidas, ¡lo cual es una propiedad interesante para un sistema (como Blockchain) que necesita manejar un estado en constante cambio!
Merkleizándolo
Todo lo que queda es agregar esta especie de característica de "huella digital" a los Patricia tries que es tan importante en los árboles de Merkle. ¿Podemos combinar lo mejor de ambos mundos?

¡Por supuesto! Con dos consideraciones muy simples:
- El índice o identificador de un nodo, que define su ubicación en el árbol, está determinado por la dirección de una cuenta
- Los nodos internos — que tienen dos hijos — mantienen un registro del hash de la concatenación de los hashes de sus hijos
En particular, esta consolidación de hashes en los nodos padres "fluye hacia arriba" en el árbol, de modo que el nodo raíz contendrá un hash que es único para el árbol, y depende de cada una de las hojas, ¡justo como en los árboles de Merkle!
Una Advertencia
Aquí viene una curva: aunque hemos sugerido fuertemente que Ethereum usa tries de Merkle Patricia — y normalmente verás documentación flotando por internet afirmando esto — , la verdad es que no lo hace.

Ethereum actualmente usa tries radix, con un radix de . ¡Tries hexadecimales, podríamos decir!
A pesar de no ser técnicamente correcto, la comunidad parece haber adoptado el término "Patricia Merkle trie" de todos modos. Podríamos al menos decir que estamos trabajando con una versión modificada, pero la realidad es que son simplemente tries de Merkle radix-16, con la restricción de que cada nodo tiene o bien ningún hijo, o al menos dos (y hasta ) hijos.
La restricción anterior permite la Merkleización, así que no tenemos nada de qué preocuparnos en este aspecto — los nodos internos siempre tendrán suficientes hijos para que el proceso funcione. ¡Genial!
Hinchazón
Así que nos hemos decidido por una estructura para almacenar cuentas. En este punto, deberíamos notar que el árbol de Merkle Patricia Modificado será enormemente grande, porque hay muchas cuentas que rastrear.
Y esto significa problemas — después de todo, el trie de estado tiene que ser almacenado en algún lugar, y ese lugar necesita tener mucha memoria disponible. Esta situación fue bautizada como hinchazón de la Blockchain o hinchazón de estado, y es una preocupación que las Blockchains aún están tratando de resolver.
El equipo de Ethereum tiene pleno conocimiento de este problema, y uno de los principales hitos en la evolución de esta Blockchain es tratar de reducir la hinchazón, en un posible evento futuro que llaman "La Purga". ¡Aquí hay una excelente publicación del mismísimo cerebro detrás de Ethereum entrando en mucho más detalle!
También vale la pena mencionar que hay otros futuros posibles previstos por el equipo de Ethereum, con su propia investigación en curso. Una de esas alternativas fue nombrada "El Borde", que propone cambiar el almacenamiento del trie de Merkle Patricia por otra estructura llamada árboles Verkle, posiblemente combinada con pruebas STARK.

Es mucho para asimilar — ¡y creo que es más sabio comenzar por entender el estado actual de las cosas!
Independientemente, la información se almacena en nodos de la red. Pero no todos los nodos necesitan almacenar este gigantesco estado — algunos de ellos están especializados para este propósito, y un poco más. El tipo de nodos que almacenan el trie de estado son nodos completos, o nodos de archivo — mientras que otros, como los nodos podados o nodos ligeros almacenan solo una porción (o nada) del estado. Todos estos nodos tienen diferentes funciones, que podemos explorar en futuros artículos.
Almacenamiento... ¿Dónde?
Hasta ahora hemos dicho que los datos de las cuentas están almacenados en tries de Merkle Patricia. Pero eso no es completamente cierto.
Si bien es cierto que la estructura de datos es muy útil para condensar todo el estado de la Blockchain en una única raíz, nunca hemos mencionado dónde viven esos tries en el almacenamiento. Y la verdad es que no están almacenados como tales.
La verdad es que Ethereum usa una base de datos clave-valor para almacenar información.
Lo sé, impactante.
¿Por qué pasar por todos esos problemas buscando una estructura de datos adecuada, entonces? Antes de que empecemos a reflexionar sobre el significado de la vida después de esta revelación, consideremos las implicaciones aquí.
Cada cuenta está representada por algún identificador (es decir, una dirección), y algunos atributos — nonce, balance, etc. Los tries de Merkle Patricia nos dan una manera elegante de consolidar los datos en la totalidad de las cuentas de Ethereum en una única raíz, lo que funciona maravillosamente al verificar la consistencia de los datos. Pero el trie no dice nada sobre dónde viven los datos de cada cuenta.
Y así, podemos decidir almacenar los datos de cada cuenta donde queramos. Una base de datos de clave-valor resulta ser una buena elección. Hace el trabajo de almacenar el par identificador-cuenta, sin agregar ninguna característica extra que sea innecesaria para esta aplicación (te estoy mirando a ti, bases de datos relacionales).
Solo como referencia, la implementación del nodo Go Ethereum (GETH) usa LevelDB como su almacenamiento clave/valor.
Siempre y cuando los identificadores en nuestra base de datos clave-valor se usen como las rutas en el trie de Merkle Patricia, podemos reconstruir el árbol (hasheando el contenido de los nodos), y calcular su raíz según sea necesario. ¡Todo está bien!
Volviendo a la Representación del Estado
¡Genial! Tenemos nuestro trie de Merkle Patricia, almacenado en una base de datos clave-valor, alojada en algunos nodos en la Blockchain. Las hojas en el árbol contienen información de la cuenta, que definimos vagamente como un conjunto de atributos (también en formato clave-valor) hace un par de minutos.
¿No sientes que falta algo? ¿No estamos olvidando algo?

Las cuentas no son las únicas cosas que almacenar — ¡también necesitamos manejar los datos asociados con cada Contrato Inteligente!
Cada Contrato Inteligente define su propio conjunto de reglas (entraremos en eso más adelante en la serie), y crucialmente, su propio estado. Definir este estado personalizado es un arte en sí mismo — pero en última instancia, necesitaremos almacenarlo en algún lugar. ¿Puedes adivinar cómo almacenaremos esa información?
¡Probablemente lo adivinaste: en otro trie de Merkle Patricia!
Así que sí, cada Contrato Inteligente tendrá su propio trie (llamémoslo trie de contrato) representando su estado, y dicho trie tendrá un hash raíz. Y podemos almacenar este hash en el trie de cuentas, para que podamos verificar rápidamente que la información almacenada en un trie de contrato no ha sido alterada.
Esto completa nuestra representación de cuenta — solo necesitamos agregar la clave storageRoot, donde guardaremos el hash raíz de un trie de contrato, en caso de que la cuenta sea una cuenta de contrato:
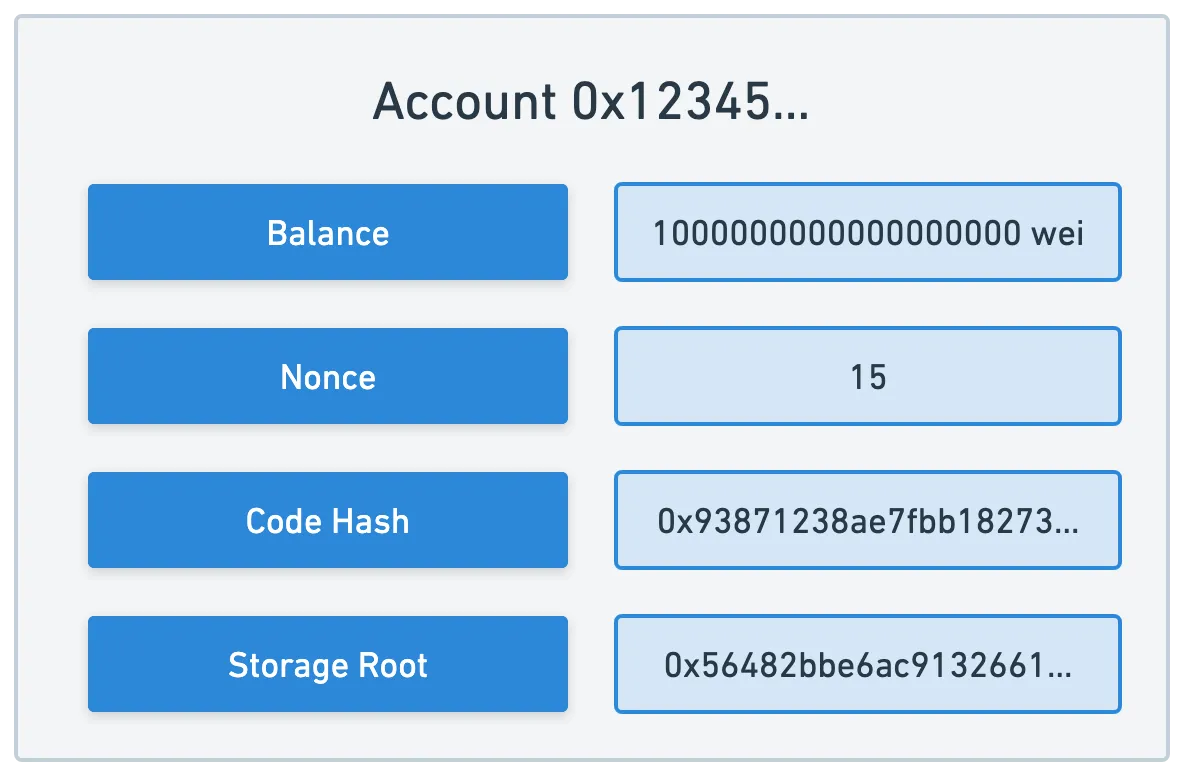
¡Y eso es todo! No era tan misterioso al final, ¿verdad?

Resumen
Esta vez, hemos discutido las estructuras de datos utilizadas para almacenar el estado de Ethereum.
Creo que aprender sobre estas estructuras de datos no solo es divertido, sino que también puede resultar útil para otras aplicaciones. Los tries Patricia se utilizan para resolver otros tipos de problemas que no están relacionados en absoluto con Blockchain, como por ejemplo las búsquedas de direcciones IP.
He dejado intencionalmente algo importante fuera del alcance de este artículo. En el caso de las cuentas, hemos definido completamente lo que debe "almacenarse" en nuestro trie de Merkle Patricia. Pero ¿qué hay de los Contratos Inteligentes?
Aún no hemos abordado cómo se modela el estado de Ethereum. En otras palabras, sabemos cómo almacenar los datos de un Contrato Inteligente, ¡pero realmente no sabemos qué estamos almacenando!
Y así, el siguiente paso en nuestra aventura nos encontrará trabajando a través de los principios operativos de los Contratos Inteligentes — comenzaremos por entender cómo se define su estado, y luego profundizaremos en cómo reciben y manejan la interacción del usuario (llamadas). ¡Hasta el próximo artículo!


¿Te resultó útil este contenido?
Apoya a Frank Mangone enviando un café. Todos los ingresos van directamente al autor.