Las Crónicas de ZK: Extensiones Multilineales
En la entrega anterior, vimos nuestra primera instancia de un protocolo que hace uso de un modelo general para la computación: los circuitos.
Aunque interesante en concepto, notamos que idealmente nos gustaría probar que un cómputo, representado como un circuito, fue correctamente ejecutado — no que sabemos cuántas entradas satisfacen el circuito (recordemos que estudiamos #SAT).
La pregunta, sin embargo, es si podemos hacer eso con nuestro conocimiento actual. Y bueno... ¡No podemos!
Ciertamente, se siente como que estamos muy cerca, y para ser justos, lo estamos. Sin embargo, llegar allí requerirá usar un pequeño artilugio matemático del que no hemos hablado hasta ahora.
Aunque las cosas pueden estar un poco más pesadas del lado matemático hoy, no pierdas de vista nuestro objetivo final: ¡probar que tenemos una entrada que satisface algún circuito!
Y así, es hora de introducir un nuevo elemento en esta serie: una pequeña herramienta que será muy útil en lo que viene a continuación.
¡Vamos a la acción!
Construyendo Intuición
Durante el artículo sobre verificación de la suma, mencioné cómo y eran dos entradas especiales debido a lo fácil que era evaluar polinomios en esos puntos.
Pero seamos honestos: en la mayoría de los escenarios del mundo real, realmente no nos importan las evaluaciones en y específicamente. Son solo números como cualquier otro — no tienen ningún significado semántico inherente.
Lo mismo no aplica realmente a la satisfacibilidad de circuitos booleanos, ¡ya que las entradas son verdaderamente variables booleanas desde el principio!
Entonces, cuando la verificación de la suma nos pide verificar sumas sobre un hipercubo booleano, surge una pregunta obvia: ¿a quién le importa?

¿Cuándo necesitaríamos sumar un polinomio sobre estos puntos específicos?
La respuesta podría sorprenderte: todo el maldito tiempo. Pero para darle sentido a todo esto, necesitamos mirar esos hipercubos booleanos bajo una luz diferente.
Codificando Información
La clave de este asunto es verlos como una forma de codificar información.
Veamos un ejemplo concreto: una simple lista de números. Supongamos que tenemos una pequeña lista de cuatro valores, digamos . Para acceder a un valor específico de esa lista, normalmente proporcionarías un índice. Entonces, por ejemplo, para obtener el valor , solicitaríamos el valor en la lista en el índice .
¡Asumiendo que estamos usando indexación desde cero, por supuesto!
Ahora, acá va una observación: los índices son simplemente enteros, y todos estos tienen representaciones binarias. Es más, esta pequeña lista tiene 4 índices posibles, que se verían así en binario:
- Índice →
- Índice →
- Índice →
- Índice →
¿Ves hacia dónde voy con esto, verdad? ¡Cada índice es simplemente un punto en el hipercubo booleano !
¡Misma información, diferente representación!
Con esto, podemos imaginar la acción de leer la información en nuestra lista en un índice dado como una función, donde ya podemos asumir que los índices son valores en el hipercubo (que en este caso, es solo un cuadrado booleano):
Que es solo notación matemática para decir "una función que toma dos variables booleanas, y devuelve algún valor en un campo".
Entonces, siguiendo el ejemplo, tenemos:
Okay, okay. ¿Pero esto no es solo más re-etiquetar sin mucho sentido?
¡En realidad, no! Lo realmente importante aquí radica en esa pequeña función que hemos deslizado tan disimuladamente a nuestro campo visual. Implícitamente, estamos diciendo que esta función es capaz de codificar datos.
De hecho, hemos visto un método para obtener dicha función: interpolación. Obviamente, lo que obtenemos de ese proceso es un polinomio. Y es a través de este tipo de codificación que el protocolo de verificación de la suma se volverá relevante.
¡Genial! Lento pero seguro, parece que estamos llegando a algún lado.
Pero quiero que notes algo: en nuestro paso por la interpolación de Lagrange, en realidad nos enfocamos en el caso univariado. La interpolación se presentó como una forma de obtener un polinomio univariado a partir de evaluaciones, que tratamos como pares .
Sin embargo, en el protocolo de verificación de la suma, hacemos uso de algún polinomio con variables, en lugar de una sola variable. Así que aquí, la interpolación como la describimos no nos llevará al tipo de polinomio que necesitamos.
Por lo tanto, vamos a necesitar algo diferente.
Extensiones Multilineales
Lo que necesitamos es una forma de ir de una función multivariada (como nuestra de arriba) definida sobre un hipercubo booleano a un polinomio multivariado. Llamaremos a dicho polinomio por conveniencia, dado nuestro paralelo con la verificación de la suma.
Y haremos esto de una manera muy especial. Porque hay dos condiciones importantes a considerar:
- Coincidencia en el hipercubo: queremos codificar algunos datos, lo que significa que debe coincidir con un conjunto de valores en el hipercubo booleano.
- Extensión más allá del hipercubo: en el protocolo de verificación de la suma, se nos requiere evaluar en puntos distintos a los del hipercubo.
Combinadas, estas dos condiciones definen precisamente el comportamiento de :
![]()
![]() Necesita ser un polinomio multivariado donde cada entrada puede ser un elemento del campo finito, y cuyas salidas coincidan con los valores codificados en el hipercubo booleano
Necesita ser un polinomio multivariado donde cada entrada puede ser un elemento del campo finito, y cuyas salidas coincidan con los valores codificados en el hipercubo booleano![]()
![]()
Sí... Eso es un montón. Vamos a desglosarlo.
Primero, estamos diciendo que necesitamos alguna función definida sobre estos conjuntos:
Esto es, toma entradas en el campo , y nos permitirá codificar un total de valores. Y para esos valores, tenemos una serie de restricciones a la función:
- codifica , entonces , donde es algún elemento en .
- Luego, codifica , entonces .
- De igual manera, .
Y así sucesivamente. Por lo tanto, requerimos que:
Que es solo notación matemática para: solo en el hipercubo.
Esta es la construcción que buscamos. Es como si estuviéramos extendiendo nuestra función original para que las entradas puedan tomar valores distintos de s y s, permitiendo valores en el campo finito más grande. De ahí el nombre: extensiones multilineales.
Pero espera, ¿por qué multilineales? ¿Qué significa eso siquiera?
Multilinealidad
Antes de que ocurra cualquier confusión: multivariado y multilineal no son la misma cosa.

Los polinomios pueden tener, como ya sabemos, diferentes grados, ya que los diferentes términos en la expresión pueden elevarse a diferentes potencias enteras. Incluso podríamos estirar un poco el lenguaje aquí y hablar del grado de cada variable, como la máxima potencia a la que una variable dada se eleva a lo largo de toda la expresión.
Decir que un polinomio es multilineal en realidad plantea una restricción fuerte sobre cómo puede verse el mismo: lo que estamos diciendo es que el grado de cada variable es a lo sumo . Para ser perfectamente claros, esto es un polinomio multilineal:
Y esto no lo es:
¡Ese único término con hace que todo el polinomio sea no lineal!
Bien... Pero, de nuevo, ¿por qué importa esto?
Resulta que imponer esta condición tiene un par de consecuencias interesantes. Verás, en principio, podríamos extender nuestra función original usando polinomios de cualquier grado. ¡De hecho, hay infinitas maneras de hacer esto!
Tomemos por ejemplo nuestra lista de 4 elementos . Podríamos construir polinomios como:
Los tres codifican correctamente la lista en , y por supuesto divergen en todos los demás puntos. Entonces... ¿Qué hace que la multilinealidad sea especial, específicamente?
Primero que nada, está el hecho de que una expresión multilineal es simple y eficiente. Estos polinomios requerirán evaluación en algún momento, y en ese sentido, el grado importa. Los polinomios multilineales tienden a ser menos costosos de evaluar que expresiones de mayor grado, y además generalmente tienen menos coeficientes, lo que también impacta los costos de comunicación.
¡Además, algunos argumentos de solidez dependen de que algunos polinomios tengan bajo grado!
Pero esto no es todo. Cuando nos restringimos a polinomios multilineales, resulta que hay solo una manera de definir para que coincida con todos nuestros requisitos. En otras palabras, una extensión multilineal (o MLE por sus siglas en inglés) de alguna función definida sobre el hipercubo booleano es única.
Diablos, lo voy a repetir en términos aún más fuertes:
![]()
![]() Hay una manera natural y única de extender una función definida en un hipercubo booleano a un polinomio multilineal
Hay una manera natural y única de extender una función definida en un hipercubo booleano a un polinomio multilineal![]()
![]()
Esto es poderoso. Tanto así, que creo que deberíamos demostrar esta afirmación.
¡Siéntete libre de saltarte esta próxima sección. Solo creo que vale la pena, ya que es una propiedad tan útil de las extensiones multilineales!
Unicidad
Para mostrar esto, primero necesitaremos una estrategia para construir tal función .
Esto es lo que haremos: para cada punto en , construiremos un polinomio que evalúe a en , y a en todos los demás puntos del hipercubo.
Eso debe sonar familiar. ¿Puedes recordar dónde vimos algo similar?

¡Sí, eso es exactamente cómo definimos las bases de Lagrange! Eso es prácticamente lo que estamos haciendo aquí.
Muy bien entonces, definamos eso:
La expresión puede verse un poco extraña, pero funciona perfectamente bien:
- Cuando los valores de son las coordenadas de , cada término evalúa a . Nota que esto es igual a cuando es o . Por lo tanto, todo el producto resulta en .
- Cuando toma algún otro valor diferente de , entonces al menos un es diferente de , entonces o bien y , o viceversa. En ambos casos, es igual a , colapsando así todo el producto a .
Para obtener nuestra extensión, solo necesitamos sumar todos estos términos juntos, multiplicados por el valor codificado en un índice dado, :
Puedes verificar por ti mismo que esta expresión es multilineal. ¡Y como tal, hemos construido una MLE válida de !
Lo que queda es probar que esta expresión es la única MLE posible para .
Voy a empezar a abusar un poco de la notación ahora, para mantener las cosas un poco más condensadas. Cuando digo , simplemente asume que es un vector. ¡Esto tiene sentido en el contexto en el que estamos trabajando, después de todo!
Para hacer esto, haremos algo bastante inteligente. Supongamos que y son dos MLEs válidas para . De ellas, construyamos este polinomio , que también es multilineal:
Debido a que y son MLEs válidas, tienen los mismos valores en el hipercubo booleano, lo que significa que esos valores serán raíces de .
Más comúnmente, esto se expresa como: se anula en .
Sin embargo, para probar que y son el mismo polinomio, necesitamos mostrar que es idénticamente — es decir, su expresión es .
Ahora, dado que es multilineal, tiene grado a lo sumo en cada variable — por lo que su grado total es a lo sumo . Como ya sabemos, un polinomio no nulo de grado puede tener a lo sumo raíces.
Pero... ¡Estamos afirmando que tiene raíces distintas!
Eso es imposible: es mayor que (para cualquier ). ¡A menos, por supuesto, que permitamos que sea el polinomio cero!
Por lo tanto, la única posibilidad aquí es que , lo que a su vez significa que . Así, la MLE es única, y es exactamente la expresión que construimos.
¿Elegante, no?

La unicidad es importante porque previene la falsificación. Con esto, quiero decir que si existieran múltiples extensiones posibles, un probador deshonesto podría intentar construir una para satisfacer sus necesidades malignas.
Pero con las MLEs, hay solo una extensión correcta. ¡El proceso de extensión obtiene protección gratis: unicidad significa que no hay margen de maniobra para los tramposos!
Calculando MLEs
¡Muy bien! Hemos demostrado que las MLEs son únicas y están bien definidas. Pero hay algo más que necesitamos abordar: practicidad.
Echemos otro vistazo rápido a nuestra fórmula:
Nota que estamos sumando sobre elementos, y cada uno de los términos involucra multiplicaciones. Ingenuamente, evaluar un solo punto en tomaría un total de operaciones. Si no tenemos cuidado con cómo usamos estas extensiones, los costos computacionales podrían explotar, haciendo que las MLEs sean imprácticas.
Afortunadamente, hay una optimización inteligente para calcular MLEs que reduce dramáticamente los tiempos de evaluación, y esto es lo que finalmente hace que estos pequeños sean muy útiles.
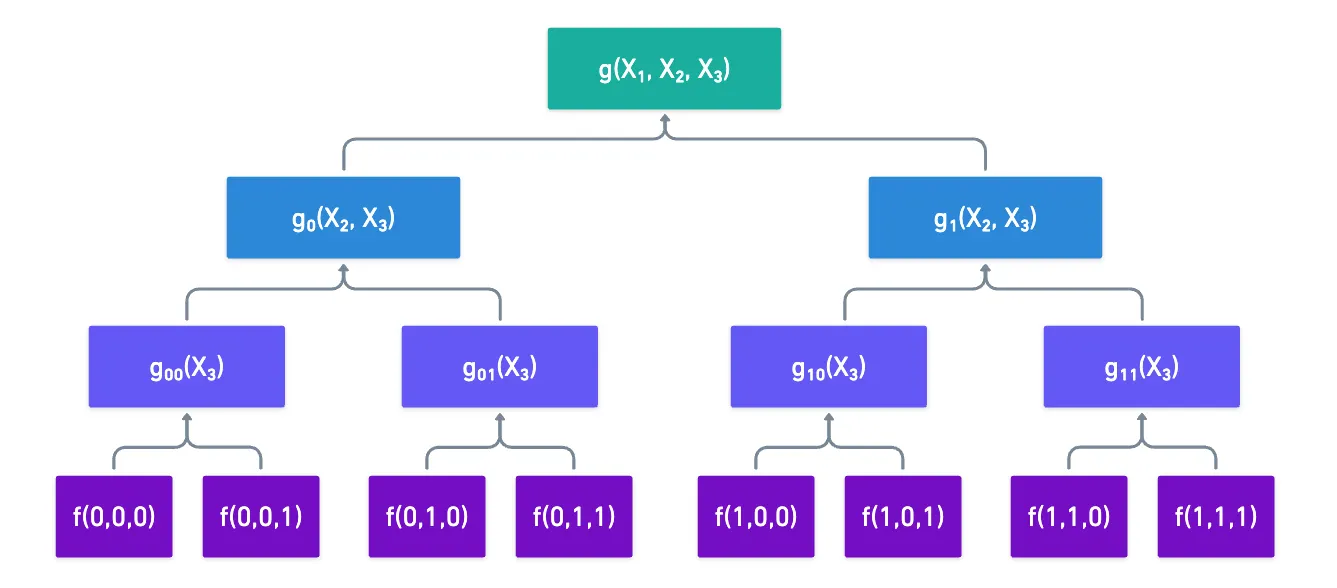
El truco, una vez más, tiene que ver con una estructura recursiva que podemos explotar. Un ejemplo aquí ayudará a conceptualizar la idea general.
Supongamos que queremos calcular la extensión de alguna función de 3 variables. El hecho de que cada variable sea binaria nos permite escribir de esta manera:
Donde y son restricciones de la función original en y respectivamente.
¡Al usar estas restricciones, hemos dividido la evaluación de nuestra MLE original en la evaluación de dos MLEs más pequeñas! Por supuesto, no necesitamos detenernos ahí: ahora podemos tomar y , y hacer exactamente lo mismo, reduciendo su evaluación a dos nuevas MLEs con una variable menos.
Una vez que llegamos a polinomios univariados, su evaluación se vuelve super simple:
Recuerda: , así como las otras variables, tomará valores del campo finito cuando estemos calculando la extensión multilineal — ¡no solo y !
Entonces, para evaluar , tenemos que ir en la dirección opuesta. Empezamos con las evaluaciones de , y tomamos combinaciones de ellas. Siguiendo nuestro ejemplo resultaría en este pequeño gráfico aquí:
La magia ocurre cuando consideramos el contexto en el que se usan estas MLEs. Verás, en nuestro buen protocolo de verificación de la suma, necesitamos calcular en puntos como estos en rondas subsecuentes:
¡Si lo necesitas, ve a revisar el protocolo de nuevo!
En cada ronda, una variable se fija a un valor de desafío , pero las variables restantes aún toman combinaciones booleanas que se repiten, y pueden ser reutilizadas.
Podemos ver esto en acción en nuestro pequeño ejemplo. Supongamos que necesitamos encontrar , y luego . La primera evaluación nos lleva a calcular y :
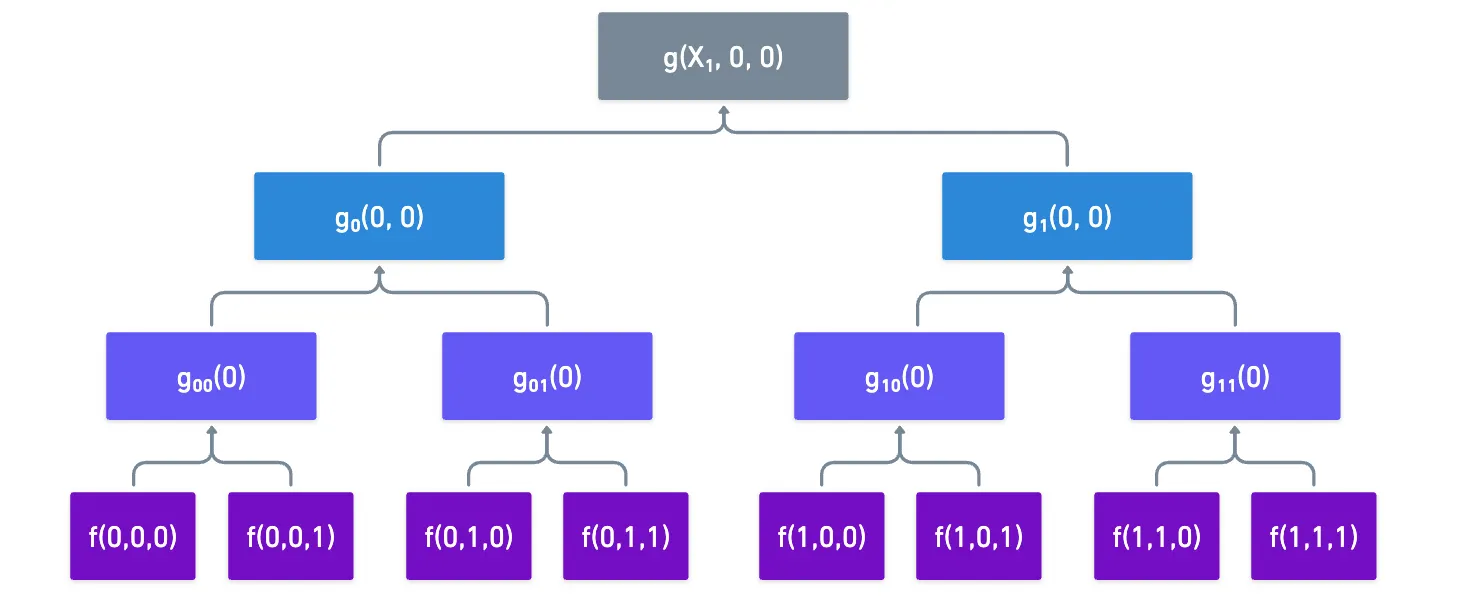
Si almacenamos esos valores para uso posterior, simplemente podemos reutilizarlos cuando se nos requiera calcular :
¡Lo que hemos hecho es usar uno de los trucos más antiguos del libro en diseño de algoritmos: memoización!
¡Todo lo que hacemos es almacenar valores intermedios cuando ejecutamos las evaluaciones completas al principio de la verificación de la suma, y luego simplemente los reutilizamos después, reduciendo significativamente los costos de evaluación!
Esta eficiencia ganada principalmente ayuda a mantener manejable el tiempo de ejecución del probador durante el protocolo de verificación de la suma, o realmente, en cualquier otro contexto donde codifiquemos datos de esta manera binaria.
¡Genial! Ahora hemos cubierto la mayoría de los trucos detrás de las MLEs. Pero antes de irnos, necesitaremos hablar de una cosa más, que resulta ser un fundamento que usaremos mucho de aquí en adelante.
El Lema de Schwartz-Zippel
La intuición que usamos hace un momento para probar la unicidad — que un polinomio no nulo de grado puede tener a lo sumo raíces — es en realidad un caso especial de un resultado más general y poderoso que usaremos muchas veces a lo largo de la serie, llamado el lema de Schwartz-Zippel. ¡Y ahora es el momento perfecto para presentarlo!
Esta es la idea: si es un polinomio no nulo de grado total sobre un campo , y elegimos valores aleatorios , , ..., de , ¿cuál es la probabilidad de que caigamos en una raíz?
Este valor resulta ser exactamente:
Mientras sea mucho más pequeño que el tamaño del campo finito, ¡entonces esta probabilidad es despreciable! Así, si elegimos un conjunto aleatorio de entradas, y realmente obtenemos , ¡entonces hay una probabilidad muy alta de que el polinomio original fuera el polinomio constante !
Esto parece simple, pero en realidad es una herramienta super poderosa. Una aplicación muy simple es mostrar que dos polinomios son idénticos: dados y , podemos definir como:
Cuando seleccionamos un punto aleatorio , y verificamos que , de hecho estamos diciendo que , lo que significa con alta probabilidad que es igual a .
¡Esto debería recordarte mucho al razonamiento que usamos durante el análisis de solidez del protocolo de verificación de la suma. Aunque no lo dijimos explícitamente, ¡usamos el lema de Schwartz-Zippel!
¡Usaremos esto mucho, así que definitivamente tenlo en mente!
Resumen
¡Muy bien, eso fue probablemente mucho! Hagamos un balance de lo que hemos aprendido hoy.
Primero, el hipercubo booleano funciona bien como una estrategia de indexación. Podríamos aprovecharlo para codificar información, ya que el índice podría servir como una entrada de alguna función, y los datos que queríamos codificar podrían ser su salida.
Luego, para usar esta función en la verificación de la suma, identificamos que necesitaba ser extendida. Así es como llegamos a las extensiones multilineales: extensiones únicas de estas funciones que ya no están limitadas a un hipercubo booleano.
Aunque no lo mencioné explícitamente, es muy fácil construir estas MLEs. Las bases de Lagrange que usamos son super simples. ¡Por esta razón, las MLEs son la opción superior al extender funciones!
Con las MLEs, podemos tomar prácticamente cualquier conjunto de datos — una base de datos, un vector, una matriz — y codificarlo como un polinomio que puede de alguna manera funcionar bien con verificaciones de la suma.
Obviamente, hay algo que no hemos abordado aún: ¿qué papel juegan las verificaciones de la suma en todo esto?
Quiero decir, codificar datos está bien y todo, pero ¿dónde está la computación?
Ahí es donde entran los circuitos. ¡Y ese será nuestro próximo destino, donde las cosas finalmente empezarán a encajar!
¡Nos vemos en la próxima!


¿Te resultó útil este contenido?
Apoya a Frank Mangone enviando un café. Todos los ingresos van directamente al autor.