Blockchain 101: JAM
Este artículo es parte de una serie más larga sobre Blockchain. Si este es el primer artículo que encuentras, te recomiendo comenzar desde el inicio de la serie.
Los tres artículos anteriores (intro, consenso, y Coretime) son más que suficientes para entender Polkadot a alto nivel. Cierto: siempre hay más que cubrir, y sería difícil esperar convertirse en un experto en solo tres artículos.
Esto es prácticamente cierto para cada Blockchain que hemos presentado: en su mayoría, tienen ecosistemas vibrantes alrededor de ellas, y simplemente demasiados detalles que cubrir. ¡Es simplemente imposible condensar todo eso en esta serie corta!
Aún así, podríamos parar aquí, y probablemente estaría bien.
Sin embargo, la escena de Polkadot fue sacudida por algunas noticias interesantes no hace mucho tiempo. Gavin Wood (el tipo detrás de Polkadot) fue y soltó una bomba enorme sobre el futuro de la red, y procedió a revelar su última creación: la Join-Accumulate Machine (o simplemente JAM).

Aquí hay una presentación del mismo hombre explicando de qué se trata:
Lo sé — este tipo de explicaciones aislamdas pueden sentirse un poco intimidantes, o al menos un poco locas.
En este sentido, JAM ha despertado cantidades iguales de interés y confusión. Recuerdo a algunos colegas siendo súper emocionados por las noticias, hablando de ello en chats grupales — pero cuando se les preguntaba sobre el tema, simplemente... No parecían saber cómo explicar nada sobre el tema, más que "sí, es lo que se viene en Polkadot".
Puedes encontrar y leer el graypaper tú mismo, pero honestamente es bastante extenso, y no particularmente ligero.
Para ser honesto, eso se sintió algo desalentador, y simplemente no traté muy duro de entender estas nuevas ideas en ese momento.
Ahora que estoy escribiendo sobre Polkadot, me doy cuenta de que JAM realmente se siente como una evolución natural. Si recuerdas, terminamos el artículo anterior cuestionando si podríamos reutilizar el algoritmo de consenso de Polkadot para validar cualquier computación — no solo las funciones de transición de estado de los Rollups. Spoiler: JAM es en efecto un intento de generalizar la computación descentralizada.
Mi objetivo para hoy es tratar de ayudar a aclarar de qué se trata todo esto, y enfocarme en los elementos centrales que definen la tecnología. Después de leer esto, espero que sea abundantemente claro por qué este es un desarrollo muy prometedor en el ciclo de vida de Polkadot.
No soy el primero en intentar esto. También recomiendo esta charla de Kian Paimani, uno de los ingenieros implementando JAM actualmente. ¡También fue uno de mis profesores en la Academy!
Bien, suficiente charla. ¡Abróchense los cinturones, y empezemos!
Diseccionando Polkadot
Hagamos un breve repaso, ¿sí?
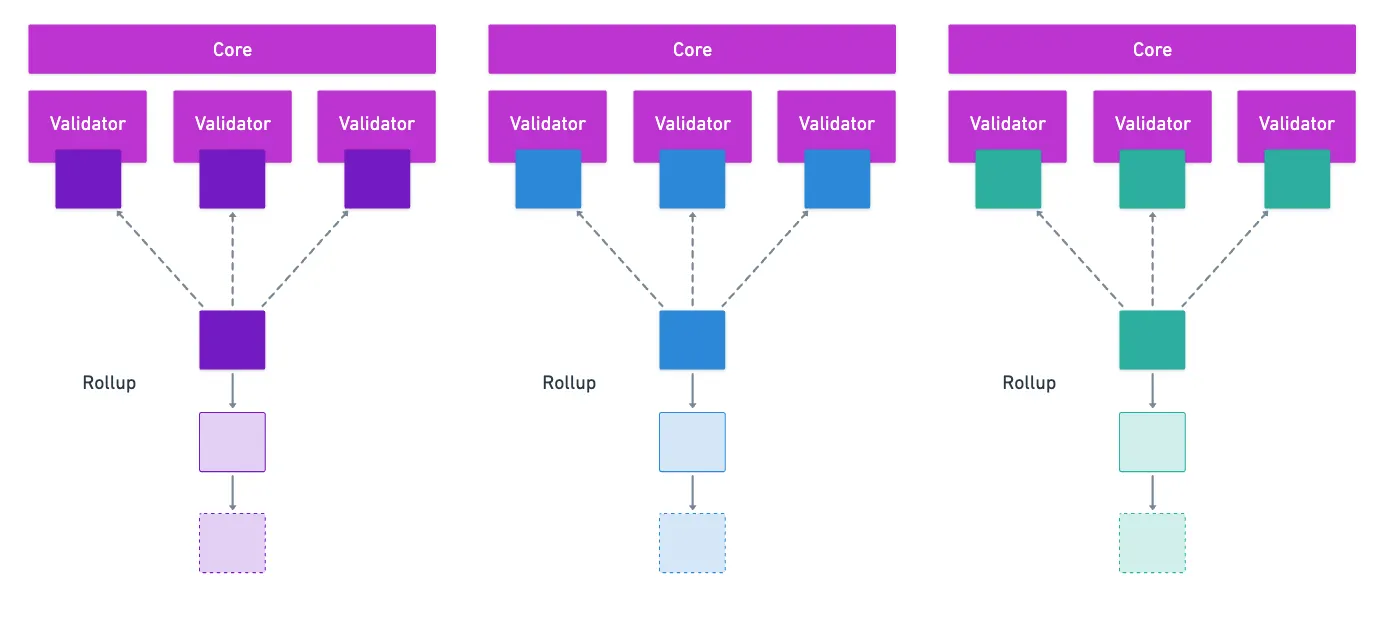
A través de ELVES, la Relay Chain asigna grupos de validadores para verificar las funciones de transición de estado de cada Rollup. Y mencionamos en el artículo anterior que cada grupo de validadores esencialmente funciona como un core — algo como una CPU, ejecutando computación en la forma de la ejecución de una función de transición de estado de Rollup, con un bloque como entrada.
Sí, es un trabalenguas — pero resume lo que hemos visto hasta ahora bastante bien.
Esencialmente, lo que tenemos es una forma de separar el grupo de todos los validadores para la Relay Chain en conjuntos más pequeños que pueden realizar computación en paralelo. Esto se conoce comúnmente como sharding — y es una característica muy buscada en el diseño de Blockchains.
Lo que Polkadot esencialmente ha logrado es una estrategia de sharding completamente funcional, y eso es bastante notable por sí solo. Pero si nos acercamos un poco más, lo que tenemos es solo una computadora distribuida, que solo ejecuta bloques de Rollup.
Así es como Polkadot está configurado. Pero ELVES y Agile Coretime juntos podrían en teoría ejecutar cualquier código — los cores (recuerda, grupos de validadores) recibirían instrucciones de ejecución, junto con posiblemente algunos datos, y simplemente harían su trabajo.
JAM es simplemente la realización de esta idea. Los Rollups serían solo un tipo de programa que podría ejecutarse en esta computadora distribuida. Todo este asunto se trata de generalizar lo que la red ofrece actualmente, abriendo posibilidades más allá de lo que estamos acostumbrados (ya sabes, Rollups y esas cosas).
Cuando se pone así, no suena tan aterrador, ¿verdad?

Por supuesto, esta visión general simple no será suficiente. Vamos a necesitar ser un poco más precisos para que esto realmente termine de hacer sentido.
Rediseñando la Ejecución
Okay. Si ya no queremos limitarnos a Rollups y Runtimes, entonces vamos a necesitar definir exactamente qué comprende una computación, y cómo debería operar en este nuevo entorno.
De nuevo, es instructivo mirar el viaje de un bloque de un Rollup estándar. En artículos anteriores, hemos visto que tres cosas clave suceden:
- El bloque es procesado por un core,
- La información para el estado resultante se distribuye en forma de codewords de Reed-Solomon (disponibilidad de datos),
- Y alguna forma de atestación se incorpora permanentemente en el estado de la Relay Chain.
La disponibilidad de datos garantiza que la ejecución puede ser verificada, mientras que la atestación es una especie de sello de aprobación de que alguna computación ha sido ejecutada — ¡solo sucede que esta computación es el procesamiento de un bloque!
Y como se mencionó anteriormente, podríamos en principio hacer el mismo proceso con cualquier computación. Lo que nos lleva a nuestro primer concepto de JAM: Servicios.
Servicios
Un Servicio realmente no es más que un programa — aunque uno con cierta estructura y propiedades.
Lo que este programa necesita definir son solo dos funciones o puntos de entrada que nos permitirán usar toda esta maquinaria de JAM: refine y accumulate.
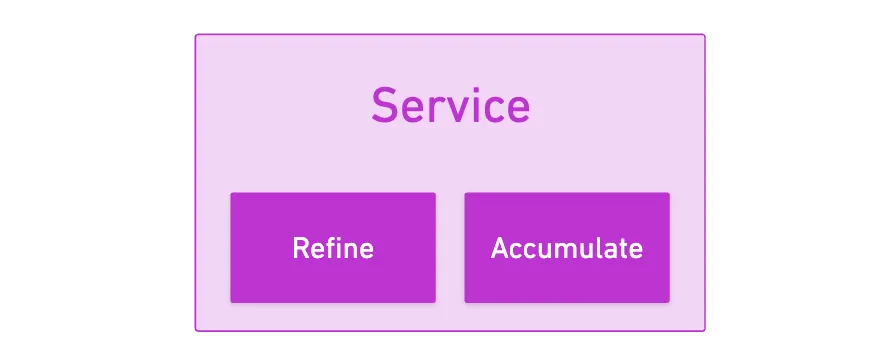
Solía haber una tercera función, on transfer, que se ejecutaría después de accumulate — pero fue removida en la versión 0.7.1 del graypaper (gracias a mi buen amigo Francisco por el detalle específico).
Además, estos Servicios pueden recibir work items o work packages, que son en esencia solicitudes para la ejecución del código estático del Servicio, definido en esas dos funciones mencionadas anteriormente.
Quizás una buena analogía sería equiparar los Servicios a Contratos Inteligentes, y los work items a transacciones. Otra comparación posible sería la del Runtime de un Rollup (Servicio), y sus bloques (work package). Probablemente puedas empezar a notar las similitudes, ¡y cómo se siente como una verdadera generalización!
Pero... ¿Qué diablos son esos nombres de funciones? ¿Refine? ¿Accumulate? ¿Qué?

No sé tú, pero no me suenan mucho sin contexto. Claro, podríamos tratar de darles sentido en el contexto de JAM — pero siento que va a ser mucho más instructivo alejarnos por un momento, y enfocarnos en lo que estamos tratando de lograr aquí: construir una computadora descentralizada que puede procesar trabajo en paralelo.
Una Computadora Multi-Core
¿Sabías que la mayoría de las computadoras modernas tienen múltiples cores de CPU adentro?
Sí. Y cuando quieres ejecutar tareas en tu máquina, querrás seguir ciertas reglas prácticas. Primero, las tareas independientes podrían ejecutarse en diferentes cores, para que no tengas que esperar hasta que una termine para empezar la siguiente. La paralelización es natural cuando las tareas están completamente desconectadas unas de otras.
Segundo, si tienes alguna tarea pesada, ejecutarla en un solo core puede no hacer el mejor uso de los recursos, así que probablemente querrás dividir la tarea, y ejecutarla en múltiples cores. Estarás ejecutando estas piezas de la tarea original en paralelo.
No hay almuerzo gratis, sin embargo — la separación viene con un costo. Es decir, porque los nuevos procesos muy probablemente no son completamente independientes, necesitarás un paso extra al final para agregar o integrar los resultados, combinándolos para obtener el resultado final de la computación paralelizada.
¡Pista, pista!
Si vas a incurrir en un paso extra para agregar los resultados, entonces tiene sentido tratar de hacer el mejor uso de cada computación en el core. Para eso, querrás darle al core toda la información que necesita para realizar cualquier tarea que ejecute. De esta manera, evitamos gastar recursos escribiendo a memoria permanente, permitiendo que el core se enfoque en realizar la computación real. Cualquier salida que obtengamos, simplemente la empujamos a alguna ubicación de memoria compartida.
En otras palabras, queremos que el core sea stateless.
Por último, si el paso de integración necesita más trabajo para completar una tarea, simplemente pondrá en cola las computaciones que vengan después — hasta que no haya más trabajo que hacer, y el proceso general esté terminado.
Bastante directo, ¿verdad? Por supuesto, esto viene con algunas complicaciones, como cómo separar tareas para ejecutar en paralelo. Pero aparte de eso, no hay misterio en todo esto.
JAM replica este modelo, pero de manera distribuida. La analogía es bastante directa:
- Los cores son grupos de validadores que procesan work items en paralelo, un ciclo a la vez. ¡Los datos de entrada crudos se refinan en una salida útil!
- La memoria compartida es sustituida por una capa de disponibilidad de datos que actúa como almacenamiento compartido del que todos los cores pueden leer.
- La integración de resultados se realiza en el paso accumulate: los resultados de las computaciones en cores individuales se reúnen cuando se vuelven disponibles.
¡Y ahí lo tienes! Bastante elegante, ¿verdad?

Ahora veamos cómo todo esto se desarrolla en la práctica durante un ciclo de JAM.
JAM Paso a Paso
El algoritmo de consenso, ELVES, ejecuta en ciclos. Esto, ya lo sabemos. ¡Por lo tanto, lo que estamos a punto de describir es un solo ciclo!
Cuando un core recibe un work package para un Servicio, lo primero que hace es ejecutar lo que se llama un authorizador. No es más que el core preguntando: ¿puede este trabajo ser ejecutado? Las condiciones a verificar aquí pueden variar — por ejemplo, podríamos querer verificar que el Coretime correspondiente ha sido pagado.
Una vez que un work package es autorizado, la siguiente cosa que el ciclo hace es llamar la función refine — recuerda, aquí es donde los datos crudos se procesan. Los work packages son paquetes de work items, y estos últimos son lo que realmente se ejecuta.
Piénsalo como ser un programa general, y sus pasos individuales.
Esta actividad de refine, como mencionamos anteriormente, es stateless. Los datos entran, se realizan algunas computaciones, los datos salen, y eso es todo.
Después, la salida de refine necesita estar disponible para el resto de la red. Los datos se codifican en codewords de Reed-Solomon, y se distribuyen entre los validadores para disponibilidad de datos.
Ya he discutido erasure coding en artículos anteriores. Es bastante interesante por sí solo, ¡así que recomiendo darle una leída si aún no lo has hecho!
Y por último, los work items procesados en paralelo se consolidan en la fase accumulate, donde los validadores leen resultados de esta capa de datos compartida, y verifican qué trabajo ha sido terminado.
Para impulsar el concepto, necesitamos notar que cada core tendrá una lista de tareas que necesita ejecutar. Supongamos que queremos ejecutar dos tareas en paralelo; nada garantiza que dos cores las procesarán al mismo tiempo.
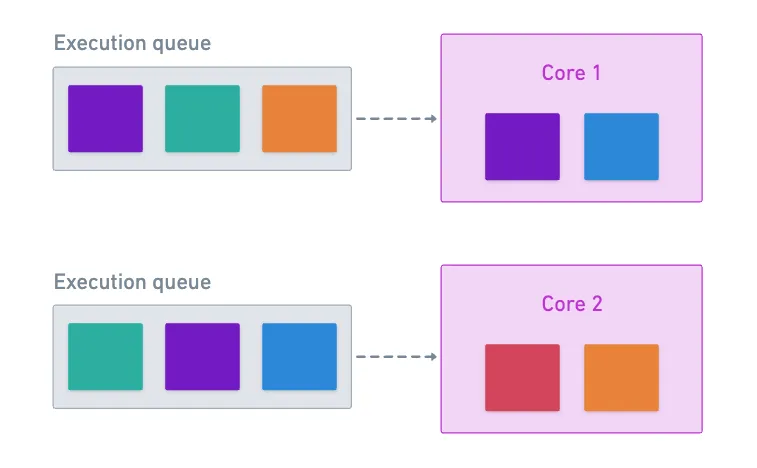
Cada core simplemente toma el siguiente work package de su cola cuando está listo. Permitir que esto suceda significa que el paso accumulate tendrá que esperar antes de que pueda considerar la tarea azul como terminada.
¡Así que sí, permite que la acumulación de resultados parciales suceda en la capa de disponibilidad de datos!
Este diseño simple mantiene el sistema flexible y eficiente, permitiéndole tanto escalar como ser más general que otros sistemas Blockchain tradicionales.
Ejemplos
Para mostrar lo que se puede hacer con JAM, quiero presentar algunas ideas de cosas que podrías hacer para aprovechar el poder de la computación paralela descentralizada.
¡Volvámonos locos!
- Red de oráculo descentralizada: imagina un Servicio que procesa y agrega datos de precios que han sido enviados a la red. Los work items contendrían datos de precios enviados por proveedores de oráculos, y diferentes cores procesarían y validarían estos envíos. Accumulate por ejemplo computaría un precio promedio ponderado, quizás filtrando envíos inválidos o atípicos.
- Sistema de detección de fraude: podríamos analizar patrones de transacción para detectar actividad sospechosa. Los work items contendrían lotes de transacciones recientes, y los cores ejecutarían diferentes algoritmos de detección en paralelo — uno verificando patrones de gasto inusuales, otro analizando el timing de transacciones, y otro evaluando si alguna billetera está en algunas listas negras conocidas. Accumulate combinaría todos los resultados del análisis para generar una puntuación de riesgo comprensiva para cada transacción. Si se exceden ciertos umbrales, podríamos activar alertas o procesos de verificación adicionales.
- Computación pesada: queremos ejecutar una simulación de plegado de proteínas, que necesita procesamiento paralelo masivo. Cada work item podría simular una pequeña porción de la estructura de la proteína, y cientos de cores podrían trabajar en diferentes partes simultáneamente. Los resultados parciales se combinarían durante accumulate para construir la estructura plegada completa. Y si se necesitan más iteraciones, pueden ser fácilmente activadas.
¡Incluso podríamos pensar en ejemplos más extremos, como ejecutar un modelo de lenguaje grande en JAM!
No estoy diciendo que ninguno de estos ejemplos sea necesariamente práctico — ¡solo que son posibles!
Con eso, hemos cubierto dos de los aspectos más cruciales de JAM: qué es (un modelo generalizado para computación descentralizada), y cómo funciona (con su modelo de procesamiento paralelo).
Sin embargo, si has estado prestando atención, puedes haber notado que algo crítico falta: ¿qué es exactamente el código que deberíamos estar escribiendo? ¿Y cómo los cores lo ejecutan?
El PVM
A este punto, sabemos no sorprendernos por tal pregunta. Las Blockchains recurren a la idea de máquinas virtuales para esto: Ethereum tiene EVM, Solana tiene SVM, y Polkadot originalmente tenía WebAssembly (WASM).
La idea es simple: queremos que todos los validadores ejecuten el mismo código bajo las mismas condiciones, así que su hardware particular no puede jugar un papel en todo esto, porque de otra manera estaríamos comprometiendo el determinismo. El determinismo es crítico para el consenso: ¿cómo podrían los nodos llegar a un acuerdo, si potencialmente podrían obtener resultados diferentes para la misma computación?
La especificación de JAM también introduce la Polkadot Virtual Machine (PVM) como su entorno de ejecución. Es prácticamente el motor que realmente ejecuta el código del Servicio cuando los cores ejecutan refine y accumulate.
¿Por qué el alejamiento de WebAssembly, puedes preguntar? Bueno, hay una plétora de razones. Concretamente, WASM tenía algunos problemas inherentes que necesitaban ser abordados desde el momento en que fue elegido como la columna vertebral para la lógica de Polkadot.
Mencionemos un par — y mientras lo hacemos, diremos algunas cosas sobre el PVM.
Determinismo
¿De nuevo?
Sí — mencionamos determinismo solo unos párrafos atrás. Resulta que es una especie de problema en WASM: tiene código no determinístico incorporado en la especificación. Cosas como la representación numérica de punto flotante por defecto.
Esta no es necesariamente una característica mala — es solo que cuando se trata de Blockchains, es potencialmente realmente dañina. Hay algunos trucos que podemos usar para evitar estos potenciales obstáculos, pero añaden complejidad, y mucha computación extra innecesaria.
En contraste, PVM es una máquina virtual basada en RISC-V.
¡He hablado de RISC-V brevemente en un artículo reciente! Nota que está basado en RISC-V, pero no es exactamente RISC-V.
Lo que esto significa es que la arquitectura del conjunto de instrucciones (piensa en opcodes) está adaptada para las operaciones que querrías ejecutar en un entorno diseñado específicamente para Blockchain. O dicho de otra manera, deshabilitas completamente todos los comportamientos innecesarios (como operaciones de punto flotante). Así, obtienes un control mucho más estricto sobre el comportamiento de ejecución, mientras mantienes las cosas eficientes y performantes.
Medición
Otro gran problema con WASM tiene que ver con la estimación de los costos para ejecutar diferentes instrucciones.
Dado que queremos cobrar por el uso de la red, es importante tener mecanismos precisos para medir el uso. A su vez, esto confiere a la red la propiedad de ser predecible — puedes estimar cuánta computación requerirás para terminar cierta tarea, y con eso, puedes estimar costos.
Modelos como EVM están claramente medidos — y la medición se encarna en la forma de gas.
WASM no se desempeña muy bien en este territorio. Fue diseñado con generalidad en mente: una especie de filosofía de "compila una vez, ejecuta en cualquier lugar". Por lo tanto, el código podría ser mapeado a un conjunto de instrucciones muy diferentes en diferentes máquinas. Significando que cómo las cosas realmente se ejecutan depende del hardware. Y sabemos que eso no está bien.
De nuevo, hay algunos trucos para tratar de obtener algo de predictibilidad en las tarifas, pero se sintieron como parches para tratar de arreglar un problema que vivía en el nivel de arquitectura.
Si no has tenido que hacer benchmarking en el Polkadot SDK... No sabes qué tan afortunado eres. Oh Dios, eso fue verdadero sufrimiento.

El PVM permite medición fácil por diseño. Claro, las instrucciones tipo RISC-V tienen que compilar a código máquina en algún punto (como con cualquier máquina virtual), pero podemos medir el esfuerzo de ejecución en términos de las instrucciones del PVM mismo.
¡Mucho como EVM!
Siendo diseñado desde cero, el PVM fue diseñado para evitar estas deficiencias. Desde la perspectiva de un desarrollador, no notarás mucha diferencia — aún puedes escribir Servicios en Rust o C, y compilan a instrucciones tipo RISC-V en lugar de bytecode WASM.
Lo que importa es que bajo el capó, JAM obtiene la ejecución determinística y eficiente que necesita para su modelo de procesamiento paralelo.
Aunque no quiero sumergirme en la especificación completa del PVM, hay una característica particular que es bastante novedosa, y realmente vale la pena destacar: la capacidad de pausar una computación.
Pausar y Reanudar
Siguiendo nuestra analogía con las computadoras de antes, podríamos examinar cómo se ejecutan los programas.
En su núcleo (sin juego de palabras), los programas son solo conjuntos de instrucciones que se ejecutan una a la vez. Mientras se ejecutan, estas instrucciones incitan al sistema a almacenar información en memoria, construyendo un contexto de ejecución. Los programas mismos son grupos estáticos de instrucciones, pero el contexto particular (o estado particular de la computación) variará.
De hecho hay varios modelos para la computación que nos ayudan a entender por qué pausar y reanudar es incluso posible en primer lugar. En particular, el PVM está modelado como una máquina de registros, lo que podría sentirse familiar porque está más cerca de las computadoras que usamos diariamente. En realidad, hay todo un campo de estudio llamado teoría de complejidad computacional que examina diferentes máquinas abstractas y sus capacidades (entre otras cosas).
Entonces, si paramos cualquier proceso en seco, ¿qué obtenemos? Veamos:
- La instrucción actual siendo ejecutada.
- Un montón de información en memoria (registros, y RAM).
¡Nada más, nada menos!
Si pausamos la ejecución, tomamos este estado mencionado arriba, y lo proveemos a otro core junto con el código completo para ejecutar, entonces debería ser capaz de continuar ejecutando el programa como si nada hubiera pasado.
Esto suena tonto, pero en realidad, la mayoría de las VMs de Blockchain simplemente no pueden hacer esto. Las computaciones se realizan hasta que te quedas sin gas, y simplemente no hay forma nativa de continuar con la computación en el siguiente bloque.
Nada fue no intencional sobre esa decisión de diseño: no solo los bloques tienen una cantidad fija de espacio, sino que los sistemas también trabajan con transacciones, que están destinadas a estar contenidas en bloques para mantener el estado general coherente.
PVM ignora completamente esta restricción. Si quieres restringir las computaciones a un solo bloque, ¡está bien! Que nada te detenga, campeón. ¿Pero qué tal alguna tarea de larga duración que nunca podría caber en un solo bloque? ¡Simplemente accumulas y continúas!
¡Esto se empareja excelentemente con cómo se cobra por la computación: no pagas por gas, pagas por Coretime!
Estaría bien sumergirse en los internos del diseño del PVM — pero creo que hemos pasado por suficientes cosas para una sola publicación.
¡Así que será una historia para otro momento!
Resumen
Con esto, hemos alcanzado la verdadera vanguardia del diseño de Polkadot. Fuimos lo suficientemente profundo para empezar a familiarizarnos con los conceptos fundamentales, pero tampoco demasiado superficial para perder el punto de lo que JAM realmente implica.
Si lo piensas, esta es una consolidación hermosa de los tres artículos anteriores: cómo las cosas comenzaron con la generalidad como meta, cómo el consenso fue diseñado con sharding en mente, cómo un modelo completamente diferente fue creado para pagar por computación, y por último, esto: cómo todo se junta como una verdadera computadora descentralizada, en lugar de solo una tecnología de ledger descentralizado.
Como corolario:
JAM no es solo una actualización incremental — es un rediseño fundamental de lo que una Blockchain puede ser.
Es una idea súper ambiciosa, seguro.
Sin embargo, uno no puede evitar preguntarse sobre la adopción. No hay duda de que JAM es una gran hazaña de ingeniería — ¿pero será usado? ¿Vivirá a la altura del hype? ¿Puede ser la próxima Blockchain asesina, o a nadie le importará la computación paralela descentralizada?
Solo el tiempo lo dirá. Equipos alrededor del mundo se están apresurando a crear implementaciones funcionales de JAM, así que tendremos que esperar un poco hasta que veamos toda esta historia desarrollarse.
¡Y honestamente, es bastante emocionante!
Con Polkadot detrás de nosotros, uno pensaría que no hay mucho menos que cubrir — e de hecho, nos estamos acercando al final de la serie.
Pero hay algunas peculiaridades de las que aún no hemos hablado, una de las cuales es una palabra de moda moderna: pruebas ZK. Están lentamente abriéndose camino en el espacio Blockchain, y en el próximo artículo, quiero explorar cómo pueden impactar el futuro de esta tecnología.
¡Te veo pronto!


¿Te resultó útil este contenido?
Apoya a Frank Mangone enviando un café. Todos los ingresos van directamente al autor.