Blockchain 101: Rollups
This is part of a larger series of articles about Blockchain. If this is the first article you come across, I strongly recommend starting from the beginning of the series.
With Ethereum behind us, one would be tempted to move onto other big Blockchain names such as Solana, Polkadot, Hedera — just to name a few.
Don’t worry, we’ll get there.
But the truth is, we cannot possibly leave the Ethereum space without talking about Rollups. These are pivotal to the success of the ecosystem in the long run — so much so that Ethereum has adopted a rollup-centric roadmap as its strategy for growth and adoption.
So today, we’ll really round up Ethereum by talking about these rollups, which are key pieces to its landscape. Let’s go!
The Scaling Problem
Everything starts with the search of a solution to a problem.
The technology behind Ethereum is a fantastic feat of engineering — no doubt about that. And even though it solves many problems gracefully, it still has its flaws.
One of the main problems is throughput.
The most common metric to evaluate throughput is to measure transactions per second (TPS). And it that field, Ethereum processes a grand total of around 15–20 transactions per second.
Not much, if we ever want to have millions of people using the network!
In contrast, networks we use every day to process our transactions, like the Visa network, have much higher TPS, clocking at tens of thousands.
So yeah, quite the difference.
For mass adoption to happen, we need our beloved Blockchain systems to process transactions faster. It’s just how it is.

But we already know many of the inner workings of Ethereum at this point. Thus, we may ask ourselves: why can’t we adjust a few things, like the slot time, and have Ethereum process transactions faster?
The answer is a very familiar one: it’s not that simple.
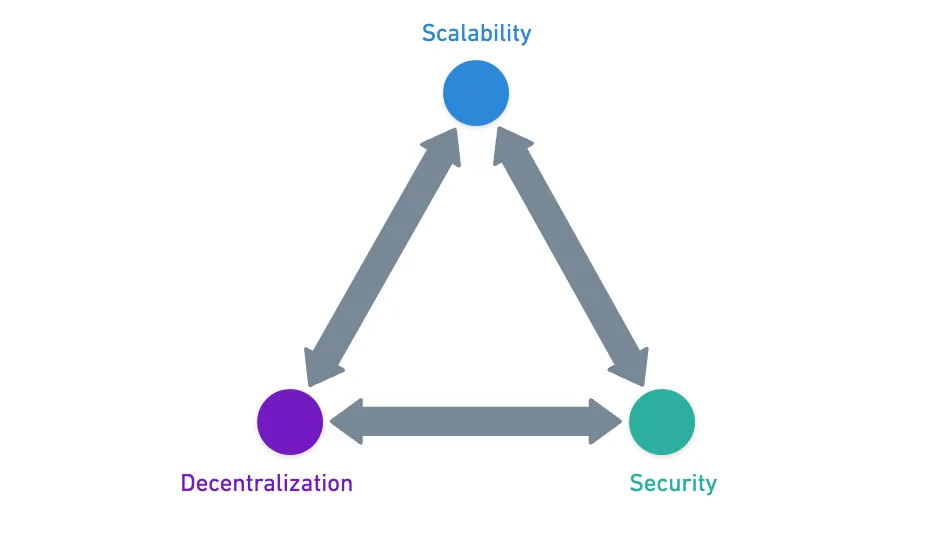
The Blockchain Trilemma
Whenever we design a Blockchain or Distributed Ledger Technology (DLT), there are three factors we need to worry about: security, scalability, and decentralization.
This is very akin to the CAP theorem in database design, which states that it’s extremely hard to provide consistency, availability, and partition tolerance at the same time.
As you might expect, the problem is that it’s really hard to be good at those three points at the same time.
Let’s consider our trusty Ethereum. The security part is very much covered, because of all the economic guarantees and validation processes we’ve talked about in previous articles. Then, the network has a myriad of validators, meaning that it’s on the high end of decentralization. So far, so good.
But you see, scalability is a problem — because the network has that many validators, it needs time to correctly coordinate them and orchestrate the production of blocks. By design, it needs to be on the slower end not to compromise security and decentralization.
Sure, we could reduce the number of validators, but that would compromise decentralization.
Or we could reduce slot time, but that would not give validators enough time to vote properly, which could compromise security.
This is known as the Blockchain Trilemma, and it’s one of those concepts you’ll see popping up every now and then.
My advice is: if someone claims to have solved it, double check! They most likely haven’t!
So you see, it’s a balancing act. And at least with its current architecture, Ethereum cannot hope to solve everything.
Unless...
Rollups
What if we could solve scalability separately?
The problem is simple: scaling (getting higher TPS) cannot be achieved without compromising other important aspects of the network. But we can do stuff outside of the Blockchain, and use Ethereum as a sort of settlement layer. Something like this:
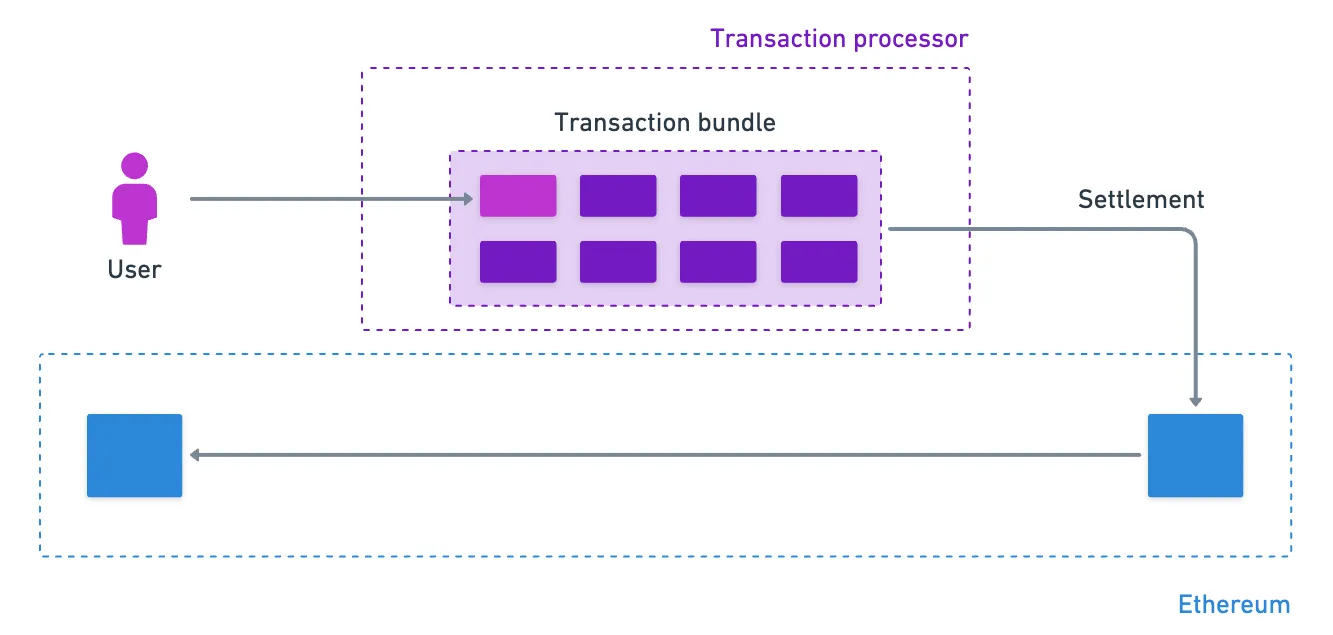
These transaction processors that live off-chain (not directly on Ethereum) are called rollups. They’re are also commonly known as Layer 2s (L2), which reflects their role of adding enhanced functionality to the base layer, often called the Layer 1.
In our case, the Layer 1 is of course Ethereum. But the concept is generalizable to other Blockchains.
Fantastic! With this, we might be able to make some progress in terms of scalability.
Until we notice that now we have a new problem: we need to figure out how to bundle transactions effectively and securely, and what to write to the Layer 1.

Don’t panic. Let’s take this slow.
Let’s go through the requirements again. These rollups just need to receive transactions and process them. Remember, a set of transactions takes us from some state into some other state — so all we need is to order said said transactions, and we’ll then have a recipe of how the change in state occurred, and... Wait a second...
That sounds awfully like a Blockchain!
Rollups as Blockchains
Sure as hell, rollups are also Blockchains. They organize transactions, and then sort of compress them, and post them into the Layer 1. And by doing this, the transaction history of the Layer 2 is permanently available on the Layer 1.
One question might be stirring up in you at this moment, so I’m just gonna say it:
![]()
![]() Wouldn’t this mean that rollups have the same trilemma problem?
Wouldn’t this mean that rollups have the same trilemma problem?![]()
![]()
Yes, they do. But the key idea here is that these rollups can put their focus on other parts of the trilemma — they don’t need to abide by the same rules that Ethereum (the Layer 1) does.
So, what strategies do they use? You’ll find that there are two main flavors for rollup strategies: Optimistic Rollups, and Zero-Knowledge (ZK) Rollups.
Let’s now take a quick peek behind the scenes of both approaches.
Optimistic Rollups
As the name suggests, this strategy is all about optimism — we’re optimistic that transactions are valid.
By default, we just assume that every transaction is valid, and only ever verify them if someone challenges the resulting state.
With this idea, processing a transaction becomes faster, because we only need to group the transactions into blocks, process them, and calculate the new state. And then we simply post a claim about the new state in the Layer 1 — for example, we could post a claim about the new account balances.
Being optimistic about transaction validity has the obvious flaw of not being able to detect fraudulent or malicious transactions.

There’s a solution to this of course, and a very simple and elegant one at that: just have a challenge period where anyone can dispute a claim.
If someone identifies a fraudulent transaction during this period, they can submit proof of the fraud, and then the rollup proceeds to verify said proof. And if the network identifies the fraud as legitimate, then those transactions are simply reversed.
To round things up, once the challenge period for a claim is over, then we assume those transactions are finalized.
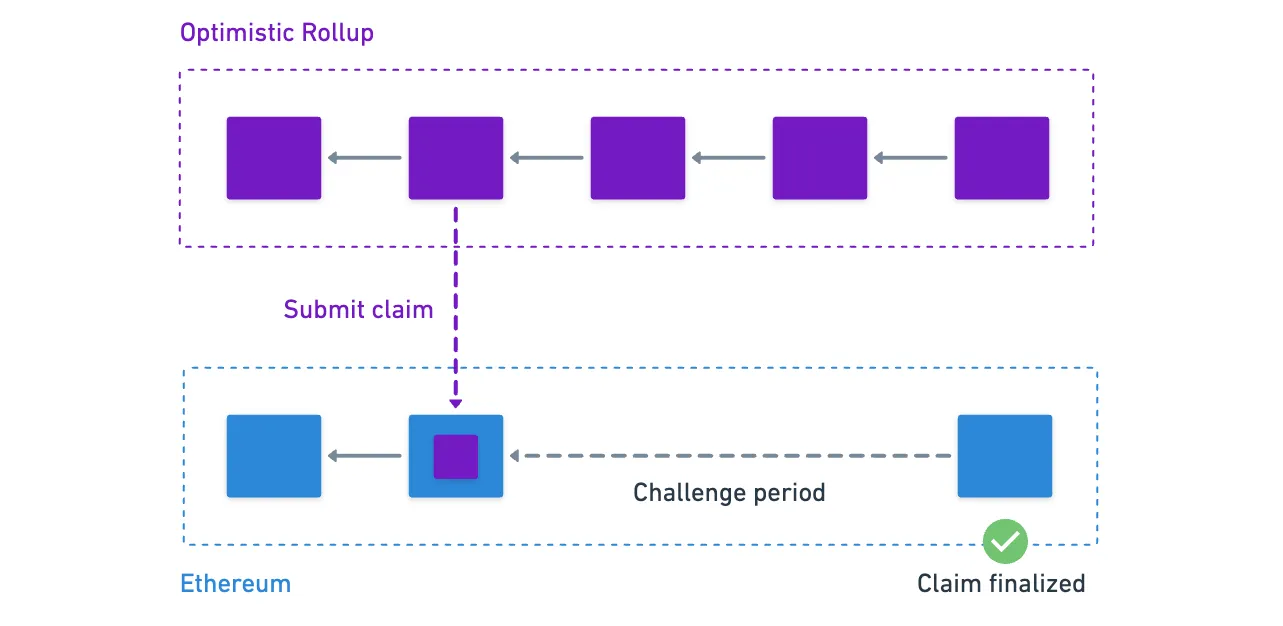
So you see, it’s a compromise again. Security is not as strong as Ethereum’s, but this allows for faster transaction processing, enhancing scalability. The trilemma at its finest!
A typical challenge period is around days. It’s not ideal, of course — but what we lose in this sense, we may gain in speed. Blockchains such as Arbitrum or Optimism work using this rollup strategy, and are theoretically able to have better TPS numbers.
Here’s the comparison of Ethereum vs Optimism, and Ethereum vs Arbitrum.
So that’s the idea, in a nutshell! As always, there’s much more to say about each and every Optimistic Rollup, but we’ll defer the finer details to some other time.
For now, let’s talk about the more mathematical rollup sibling.
Zero-Knowledge Rollups
These rollups take a radically different approach.

In these type of rollups, transactions are no longer considered valid until proven otherwise — transactions do need to be verified. What happens is that, after validation, transactions are batched, and something very different happens: a cryptographic proof of the validity of the batched transactions is generated.
This proof is what’s submitted to the settlement layer — our Layer 1 (L1). The interesting bit is that now the L1 can verify the proof in order to accept the claim submitted by the L2. Once verified, the compressed transaction data is available on the L1.
But if every transaction needs to be verified, how is this type of rollup any faster than the settlement layer?
The trick is where and how the verification happens.
Transaction verification happens off-chain, on powerful computers specifically designed for this task. These computers are also able to create a compact mathematical proof (normally a zk-SNARK or zk-STARK) that essentially says: “hey, I’ve checked all these transactions, and they’re all valid”.
Generating this proof is computationally intensive, but verifying the proof on Ethereum is relatively cheap and quick — so we can bundle hundreds or even thousands of transactions into a single proof submitted to the Layer 1.
Ok, cool. All benefits, so far — and we didn’t even mention that you get very fast finality. So what’s the catch? There’s always a catch.

The main sacrifice here is decentralization. And for two main reasons:
- Generating these proofs requires specialized algorithms. The complexity makes it harder for developers and organizations to contribute to these systems in a meaningful manner — so we could say that knowledge is somewhat centralized.
- Also, the proof generation requires powerful hardware. Most ZK Rollups just have a few sequencers, which are the systems in charge of verifying and bundling transactions — so again, the ability to produce blocks is centralized.
So yeah, nothing’s for free!
Popular ZK rollups include zkSync, StarkNet, and Polygon zkEVM. They’re gaining traction due to their superior finality and scaling properties —although to do this, they need to compromise centralization a little.
Costs
We’ve been focusing quite heavily on TPS, but the truth is that this is not the only added value rollups bring to the table.
Actually, if you were paying attention, you may have noticed that the TPS numbers for Optimistic Rollups were not much better than those of Ethereum!
There’s another very important value proposition in rollups, and its related to transaction costs.
Ethereum’s Fees
In Ethereum, gas fees are a key part of the network’s design. They ensure the network keeps working in periods of high demand — but at the same time, make our transactions very costly.
The fundamental reason Ethereum fees are high is simple: limited blockspace. Each block can only fit a certain amount of computation, which we measure in gas units, as we saw in the previous article. Users compete for this scarce resource through a fee market. When demand exceeds supply, prices rise.
But our main topic for today is rollups! What can these systems do to reduce costs?
The Rollup Solution
There are essentially three reasons (or mechanisms) that help rollups dramatically reduce fees: data compression, cost distribution, and off-chain execution.
- We already saw how rollups compress transaction data before sending a claim to be settled in Ethereum. This means that we save blockspace — making it so that the rollup transactions don’t directly compete for the resource.
- Then, there’s the fact that when bundling transactions, the cost of the settlement transaction is spread across all the transaction in the batch. If the settlement transaction costs , and the batch contains transactions, each transaction will effectively cost !
- Finally, gas fees are related to computation — and since rollups execute logic off-chain, computation is much cheaper, and can follow other fee models.
Having lower fees is a very important selling point for these networks. High transaction fees might (and do) drive users away from Blockchains, and a network without users is just a useless piece of highly complex software.
Gotta be mindful of your budget, dog.

All in all, the conclusion is that rollups are very important for the ecosystem.
Challenges
Okay! Those were the good things about rollups. Time to talk about the undesired consequences and challenges.
Cause’ nothing’s for free in the Blockchain world!
State Fragmentation
Rollups are great for the overall goal of increasing throughput and reducing costs. I think we can be convinced about that much by now.
However, each rollup has its own history of transactions. The events that are recorded in Optimism are completely different from the ones registered in Polygon. They have no recollection of each other.
Why is this a problem? Picture this: You have on Arbitrum, and want to use a cool new DeFi app that’s only available on zkSync. What do you do?
You need to bridge your assets from one rollup to another.

This bridging process costs gas fees on both sides, takes time (especially for Optimistic Rollups), introduces additional security risks, and above all, creates a poor user experience.
Also, we can talk about liquidity fragmentation — the ETH issuance is not available in a single chain, but scattered across many different systems. This makes markets less efficient and more expensive, which in turn, makes them less attractive.
We might be tempted to just dismiss this as a minor inconvenience. But it’s not — it’s a fundamental challenge to composability. Composability means that any Smart Contract can interact with any other Smart Contract in a single transaction. With rollups, creating these cross-rollup interactions is much more complex — and this feature might be very important for the success of the ecosystem.
Data Availability
The second challenge is slightly more technical, but equally important: data availability.
For a blockchain to be secure, users need to be able to verify the current state. This requires access to the data (transactions) that produces that state.
Rollups post said data to Ethereum, which ensures it remains available. But this creates a sort of tension:
- Posting more data makes systems more secure and transparent.
- But posting more data also means higher costs for users.
This means that rollups need to balance how much data they post. If they post too little, their security could be compromised. But if they post too much, fees can go up, negating one of the main benefits of rollups.

This challenge is so important, that it’s become a key part of Ethereum’s rollup-centric roadmap. Proto-danksharding (EIP-4844) is specifically designed to make data availability cheaper for rollups.
In the meantime, some rollups are exploring alternative data availability solutions, including:
- Data Availability Committees (trusted groups that store data)
- Validiums (which use external data availability layers)
- Various hybrid approaches
And, as you should expect at this point, each approach makes different trade-offs between security, costs, and decentralization.
Summary
Alright, that was quite the journey!
I reckon it might have gotten a little technical on the end. Sorry for that!
Importantly, we saw how rollups take a pragmatic approach to scaling. Rather than trying to solve the blockchain trilemma directly, they work around it by creating a layered architecture, where each layer can optimize for different properties.
And we also saw how this comes equipped with its own set of challenges.
This is an ongoing story, and we’ll see it unfold in the coming years. It’s for sure gonna be exciting!
All the while, there are other ecosystems trying to come up with their very own solutions.
So next time, we’ll start slicing up another such Blockchain: Solana, one of the big contenders for that coveted third spot in the list of Blockchain giants. It’s another big model shift, so be ready for some new ideas!
Until then!


Did you find this content useful?
Support Frank Mangone by sending a coffee. All proceeds go directly to the author.