Las Crónicas de ZK: Hashing
Es bastante increíble que hayamos llegado hasta aquí usando solo campos finitos y polinomios, ¿no?
En cuanto a protocolos, incluso llegamos a nuestro primer sistema de prueba general en forma de GKR. Y en el departamento de teoría, nos adentramos en conceptos bastante profundos, conectando diferentes tipos de problemas, y proporcionando una base teórica sólida para muchas cosas por venir.
Pero quiero decir, vamos. Si te interesa esto de alguna manera, sabes que hay algunos elementos que aún no hemos tocado. Y por supuesto, uno prominente que aún nos falta en nuestra búsqueda de ZK son las funciones de hash.
Así que hoy, finalmente es hora de incorporarlas a la mezcla. Por simples que puedan parecer, desbloquearán algunos superpoderes cruciales para nuestros sistemas de prueba.

¡Empecemos echando un vistazo a qué es exactamente con lo que estamos tratando, y luego pondremos estas cositas de hash a buen uso!
Funciones de Hash
Probablemente ya hayas oído hablar de las funciones de hash. Están en todas partes: almacenamiento de contraseñas, verificaciones de integridad de datos, firmas digitales, y más. Son verdaderamente un comodín.
Estoy dispuesto a apostar que probablemente sabes qué son y cómo funcionan, pero por el bien de la completitud, solo repasemos una breve explicación.
¡También tengo un artículo de nivel introductorio sobre este tema, que quizás quieras revisar!
Para hacer esta introducción rápida, una función de hash es simplemente una función que toma alguna entrada, la mezcla, y produce una salida que es completamente irreconocible de la entrada.
¡Oh, por cierto, usualmente nos referimos a la salida de una función de hash como el hash del valor de entrada!
Eso es todo lo que hace, realmente. "Hachear" literalmente significa cortar algo en pedazos más pequeños y cocinarlo, mezclándolo efectivamente y creando algo nuevo a partir de la mezcla. Como esas deliciosas papas hash que todos conocemos y amamos.

Sin embargo, en contraste con nuestro paralelo culinario, este corte ocurre de una manera muy específica, otorgando a las funciones de hash algunas propiedades especiales:
- Son deterministas: cada vez que pasamos la entrada a través de la función de hash, obtendremos exactamente el mismo valor, sin importar cuántas veces lo intentemos.
- Son difusivas: pequeños cambios en la entrada producirán cambios tremendos en la salida. Esto también se llama a veces efecto avalancha.
- Son impredecibles: no podemos saber de antemano cuál será la salida solo analizando una entrada.
- Son irreversibles: no podemos saber cuál era la entrada analizando la salida. Para ser un poco más precisos, lo que estamos viendo aquí es resistencia a preimagen: es increíblemente difícil encontrar una entrada que produzca una salida dada. Debido a esto, las funciones de hash a veces se llaman funciones unidireccionales.
En la mayoría de los casos, también nos importa la resistencia a colisiones, lo que significa que encontrar dos entradas que produzcan la misma salida (o incluso salidas que coincidan parcialmente) es muy difícil.
Construir una función para cumplir con estos requisitos no es una tarea fácil, pero tampoco es imposible.
Sin embargo, una vez que obtenemos tal construcción, sus propiedades la hacen adecuada para una plétora de aplicaciones, una de las cuales necesitamos hablar justo después de esto.
Árboles de Merkle
La existencia de estas funciones de hash nos permite construir estructuras de datos complejas alrededor de ellas, de las cuales quizás la más conocida es el árbol de Merkle.
Los árboles de Merkle vienen en varias formas, pero la versión más simple es la de un grafo en forma de (sí, lo adivinaste) árbol. Sin embargo, no es tu grafo "normal", por así decirlo.
Empecemos con el ejemplo más simple posible, y eso nos permitirá entender cómo funciona esto y por qué la estructura es útil a mayor escala. Va así:
- Toma dos cadenas cualesquiera. Elige lo que quieras: desde palabras simples como "hola" y "mundo", hasta los dos primeros párrafos de Lorem Ipsum.
- Hachea ambos. Podemos usar una función de hash común para esto, como SHA256.
- Ahora, toma los dos resultados, y concadénalos. Es decir, simple concatenación de cadenas.
- Finalmente, hachea de nuevo.
Lo que acabas de hacer se ve así:
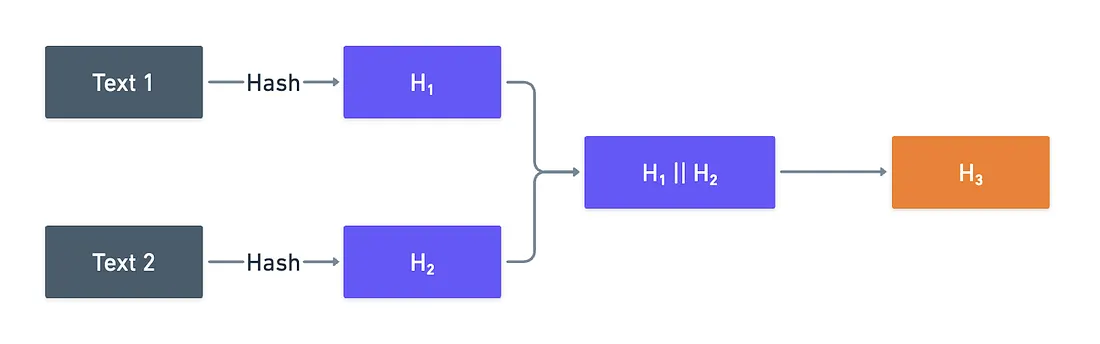
¿Por qué hacer todo esto, te estarás preguntando? Tres razones, en realidad.
La primera tiene que ver con cómo la información está unida: debido a las propiedades de los hashes, un pequeño cambio en cualquiera de los textos originales resultará en un valor de salida totalmente diferente (al que llamamos la raíz del árbol). Además, si el hash es resistente a colisiones, significa que es realmente difícil encontrar otros textos que produzcan la misma raíz.
Todo esto para decir: la raíz es una garantía de la integridad de los datos originales. Cualquier cambio minúsculo, y la raíz cambiará dramáticamente. Así que esto funciona como una forma de comprometerse con esos valores iniciales.
En segundo lugar, veamos qué sucede cuando escalamos este proceso. ¡Nadie dijo que deberíamos limitarnos a dos entradas! De hecho, podríamos hacer este mismo proceso con 4, 16, 64, o incluso miles de valores originales, todos siendo reducidos a una única raíz. Por lo tanto, la segunda razón por la que hacemos esto es compresión: podemos comprometernos a un conjunto enorme de datos, cuya integridad puede verificarse contra un único pequeño valor.
"Pero Frank" — puedes preguntar, "¡los hashes ya comprimen! ¿Por qué no simplemente hachear todas las entradas juntas de una vez?". Y estarías en lo correcto. De hecho, una función de hash toma una entrada en algún dominio potencialmente sin restricciones , y la mapea a una cadena de bits de una longitud fija:
Entonces... ¿Por qué no simplemente hachear todo, y terminar con esto?
Eso nos lleva a nuestra tercera y última razón: la capacidad de generar pruebas de inclusión. Los árboles de Merkle nos permiten probar que una única hoja de entrada es parte del árbol, por lo tanto está vinculada a la raíz, proporcionando hashes intermedios a lo largo del camino hacia la raíz, que se llaman rutas de Merkle, o rutas de autenticación. Así:
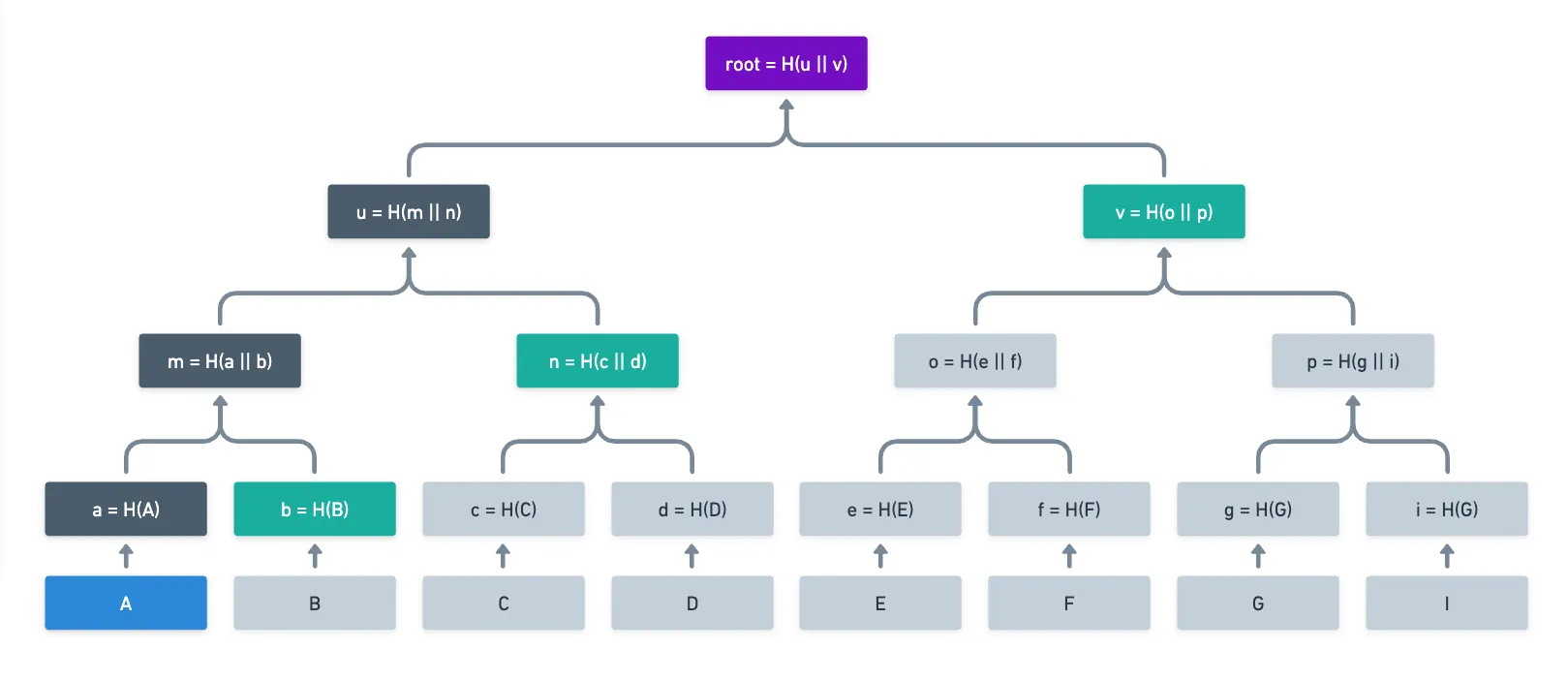
En lugar de tener que proporcionar todos los datos originales para recalcular la raíz, alguien que quiera probar que era parte del conjunto original solo necesita enviar los valores de los nodos verdes, y alguien que verifique esto puede encontrar fácilmente la raíz por sí mismo.
¡Ese es un truco agradable y útil!
Especialmente en el contexto correcto: por ejemplo, algunas blockchains como Bitcoin usan árboles de Merkle para comprimir las transacciones en un bloque, proporcionando efectivamente una forma rápida de validar la inclusión de una transacción en dicho bloque.
Pero estamos aquí para computación verificable y ZK. La pregunta entonces es clara: ¿son los árboles de Merkle útiles en este contexto?
La respuesta, como podrías esperar, es sí. Sin embargo, todavía estamos demasiado temprano para sacar todo el potencial de estas estructuras. Por ahora, solo puedo mostrarte la punta del iceberg... ¡Pero estoy bastante seguro de que eso será suficiente por ahora!
Compromisos Polinomiales
Hace unos artículos, cuando introdujimos por primera vez el protocolo de verificación de la suma, mencioné la idea de hacer una consulta de oráculo a algún polinomio .
En ese entonces, nos faltaban algunos conceptos matemáticos clave para realmente presentar cómo se puede lograr esto. Para ser justos, todavía nos faltan — pero los hashes comienzan a desbloquear algunas posibilidades.
Analicemos cómo podría verse tener acceso a oráculo. Supongamos que tienes algún polinomio definido sobre algún campo finito , y quieres evaluarlo en alguna entrada . Hay dos opciones aquí:
- Tienes una forma de evaluar tú mismo, confiando en ninguna otra parte.
- Le pides a alguien más que calcule , y proporcionan una prueba de correctitud.
La primera, si es posible, es la solución más simple. Sin embargo, el polinomio original a menudo no está disponible para el verificador, o al menos, sería poco práctico para ellos calcular por su cuenta.
En su lugar, el verificador podría pedirle al probador el valor . Por supuesto, el probador podría mentir — ¿cómo puede el verificador confiar en este valor entonces?
Bueno, una solución a este problema (aunque un poco loca) implica usar árboles de Merkle.

La idea es bastante cruda, pero poderosa: el probador evalúa cada entrada posible para , y condensa todos los resultados posibles en una única raíz de Merkle.
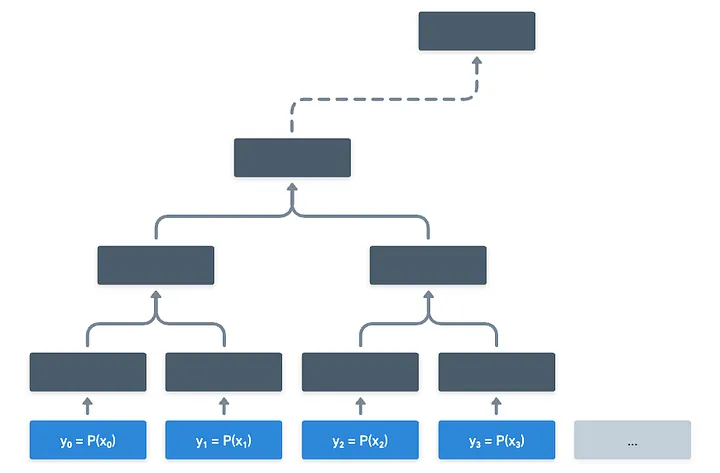
Naturalmente, este árbol puede crecer grande. Como realmente, realmente grande. Aún así, el probador necesitaría hacer esto una vez, y enviar la raíz al verificador, y eso es toda la configuración que necesitamos. Al hacerlo, el probador se ha comprometido a los valores en el árbol de Merkle, y solo puede responder con valores válidos cuando se le solicite.
Por lo tanto, la parte interesante sucede cuando el verificador pide una evaluación en algún valor .
Es importante que los valores de entrada tengan algún tipo de ordenamiento que coincida con el orden de las hojas del árbol de Merkle. El orden puede ser tan simple como , , y así sucesivamente.
Todo lo que hace el probador es proporcionar el valor de , junto con la ruta de autenticación que lleva a la raíz que el verificador ya posee!
Esto es bastante agradable, porque la prueba proporcionada puede verificarse en tiempo logarítmico. Si hay un total de evaluaciones posibles para pedir, ¡entonces la verificación ocurre en pasos!
Efectivamente, el verificador está pidiendo algún valor , y el probador está respondiendo con el valor correcto, y prueba de su correctitud (vía inclusión en el árbol de Merkle).
Se ve caro para el probador, sí, pero plausible. Solo que... Hay un gran problema con esta solución: ¿cómo sabemos que las evaluaciones en el árbol de Merkle corresponden a en primer lugar?
Eso está mucho más allá del alcance del artículo de hoy. Pero no te mentí completamente: los árboles de Merkle son útiles para esto. Digamos que hay condiciones adicionales que podemos verificar, dado el contexto apropiado.
Aún así, hemos demostrado que los árboles de Merkle pueden usarse como base para lo que llamamos compromisos polinomiales: formas de comprometerse a un polinomio, para que las evaluaciones puedan verificarse por su validez contra el compromiso cuando se soliciten.
¡Hay otras formas de hacer esto, y exploraremos más de ellas más adelante!
¡Suficientes árboles de Merkle por ahora! Los hashes se pueden usar de otras maneras en computación verificable, dos de las cuales son aún más valiosas que los árboles de Merkle para nosotros. Esas, las examinaremos a continuación.
Hashes en Circuitos
En el artículo anterior, comentamos cómo podemos convertir cualquier computación en un problema de satisfacibilidad de circuitos (CSAT).
¿Y qué son las funciones de hash, si no computaciones? ¡Eso significa que podemos convertirlas en circuitos!
¿Deberíamos, sin embargo?
Si hay algo que hemos aprendido hasta ahora, es que el costo de nuestros protocolos de prueba depende en gran medida del tamaño del circuito. Tanto nuestro sistema #SAT como el protocolo GKR se volvieron más caros a medida que aumentaba el tamaño del circuito, por lo que es razonable decir que nos gustaría mantener los circuitos tan pequeños como sea posible.
Lo que estoy tratando de llegar es esto: supongamos que escribimos algún programa que usa una función de hash, y convertimos dicho programa (sabemos que esto es posible gracias a Cook-Levin) en un circuito. ¿Qué tan grande será ese circuito?

Podemos medir el tamaño esperado de los circuitos producidos por el número de restricciones matemáticas que tienen las funciones de hash.
Piensa en estas restricciones como el número de pasos tomados para calcular el hash final. Seremos más precisos en lo que realmente son estas restricciones más adelante. Por ahora, podemos imaginar cada uno de estos pasos como una expresión que necesita ser válida para que todo el proceso sea correcto — muy similar al caso cuando analizamos circuitos en el protocolo GKR. Y cada restricción puede representarse con un pequeño número de puertas de suma y multiplicación.
Las funciones de hash tradicionales, como SHA-256, fueron diseñadas específicamente para CPUs, que usan circuitos booleanos. Hacen uso de operaciones bit a bit como , , o rotaciones, organizadas en rondas de mezcla. Y para empeorar las cosas, realizan muchas de estas rondas de mezcla (64, en el caso de SHA-256). El resultado de esto es un número exorbitante de restricciones, alcanzando fácilmente decenas de miles.
Creo que es bastante obvio que esto hace que las funciones de hash comunes sean bastante impracticables para computación verificable y ZK en general, porque hacen que nuestros esfuerzos de prueba sean muy caros.
La siguiente pregunta sigue naturalmente entonces: ¿hay funciones de hash seguras (con todas las buenas propiedades que describimos antes) que podamos implementar con circuitos pequeños?
Funciones de Hash Amigables para ZK
¡Por supuesto!
Con el advenimiento de la computación verificable, y reconociendo la necesidad de funciones de hash que produjeran circuitos pequeños, se desarrollaron algunas alternativas nuevas. Funciones de hash como MiMC o Poseidon producen circuitos mucho más pequeños en comparación con funciones de hash más "tradicionales", haciéndolas adecuadas para la representación de declaraciones.
Entonces, ¿cómo funcionan? Hay algunos trucos interesantes detrás de estas construcciones (como cómo implementan la operación S-box), pero en resumen, la magia reside en que usan operaciones nativas a circuitos aritméticos: suma y multiplicación de campos finitos.
¡También, revisa este artículo de Rareskills para algunos detalles adicionales!
Esto resulta en circuitos muy delgados, con solo un par de cientos de restricciones.
Debido a que están diseñadas para circuitos aritméticos en lugar de CPUs, estas funciones son mucho más lentas que otras funciones de hash comunes como SHA-256 o Keccak-256. Sin embargo, tienen perfecto sentido para computación verificable, donde como ya sabemos, el tamaño del circuito es rey.
Para la mayoría de las aplicaciones ZK, Poseidon parece ser la función de hash de facto de elección.
Imagino que esto ya es mucha información.
¡Toma una pausa si es necesario!
Sin embargo, he guardado posiblemente la aplicación más importante para hashes para el final. La verdad es que prácticamente no podemos continuar adecuadamente nuestro viaje sin entender el siguiente concepto. Así que todavía no los voy a dejar ir. ¡Perdón por eso!
El Problema de la Interactividad
Uno de los grandes "problemas" que puedes haber identificado con nuestros sistemas de prueba hasta ahora es la interactividad.
En nuestros diseños, un probador y un verificador tienen que interactuar entre sí, enviando mensajes y desafíos de ida y vuelta, permitiendo en última instancia que el probador convenza al verificador de la validez de alguna computación.
No es realmente que esta interactividad sea un problema — después de todo, es lo que permite que los sistemas funcionen en primer lugar. Pero al menos podemos reconocer que la interactividad tiene dos complicaciones:
- Hace que el proceso general sea lento. En cada desafío del verificador, el probador tiene que hacer alguna computación relativamente cara, que se convierte en el cuello de botella para todo el protocolo.
- Requiere que ambas partes estén activas durante toda la interacción. ¡Si una parte se desconecta o no está disponible, entonces el proceso no puede continuar!
Ok, sí... Pero ¿qué podemos hacer al respecto? ¿Hay alguna forma en que podríamos hacer esto de manera no interactiva?
¡Afortunadamente, gracias a los hashes, y a las ideas de Amos Fiat y Adi Shamir, podemos!
La Transformada de Fiat-Shamir
Hagamos una pausa por un momento, y pensemos por qué la interactividad incluso importa.
Para simplificar, enfoquémonos en el protocolo de verificación de la suma. Como un breve recordatorio, en la primera ronda, el probador envía la suma reclamada sobre un hipercubo booleano, y un polinomio tal que:
Después de verificar esto, el verificador elige algún valor aleatorio que el probador no puede predecir, y este número los impulsa a calcular algún valor inesperado , para el cual necesitan ejecutar otra ronda de verificación de la suma.
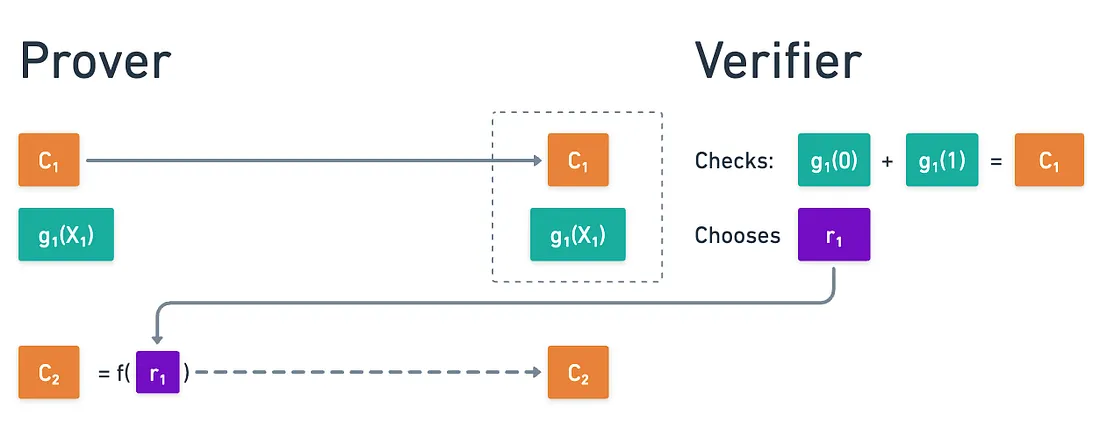
La idea clave aquí es que el probador no puede precalcular C₂, porque no pueden predecir la elección de r₁. Es esta impredecibilidad la que hace que el protocolo sea sólido, como ya vimos.
¿Y sabes qué más es impredecible? ¡Las funciones de hash!
Esa es la idea brillante de Fiat y Shamir: que podemos emular la elección del verificador tomando el hash de los mensajes intercambiados:
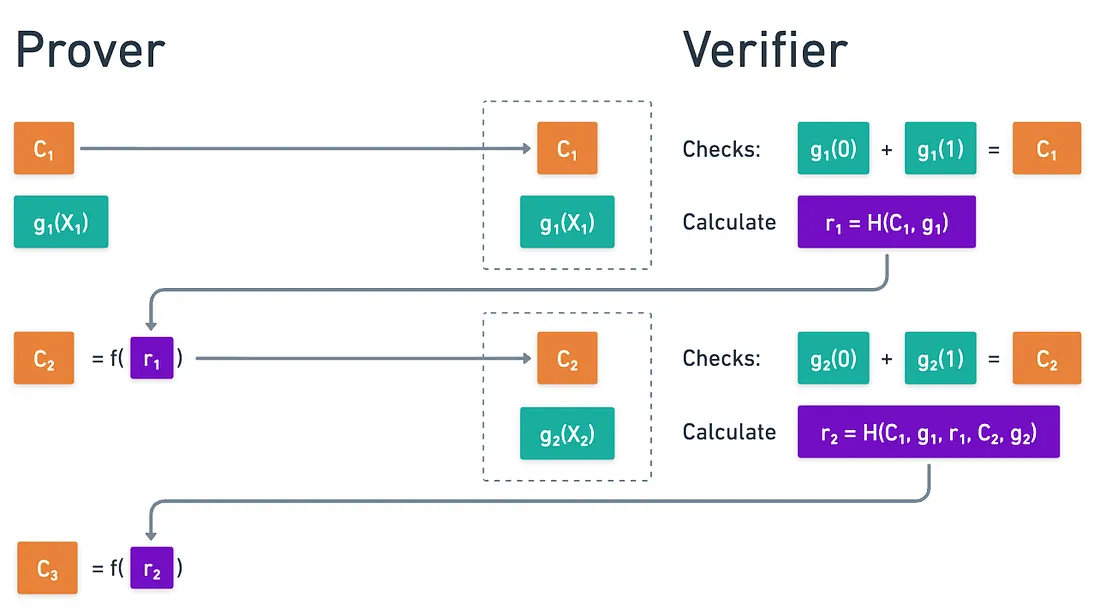
¡Genial! ¡Usamos la pseudoaleatoriedad e impredecibilidad de las funciones de hash para eliminar completamente las interacciones! Y todo lo que un verificador necesitaría verificar es que todas las verificaciones pasen, y que todos los hashes se calculen correctamente.
Esto se conoce como la transformada de Fiat-Shamir o heurística, y puede usarse para transformar cualquier protocolo interactivo en uno no interactivo, eliminando efectivamente los cuellos de botella de verificación.
Seguridad
Por supuesto, eliminar al verificador de la ecuación para la selección de desafíos significa que el probador podría manipular potencialmente las cosas.
Entonces, ¿esto es realmente seguro?
La clave está en hacer hash de la transcripción completa: todos los mensajes previamente intercambiados, incluyendo las propias respuestas del probador. Esto crea una cadena vinculante:
Y así sucesivamente.
Esto funciona porque para que un probador malicioso manipule algún desafío a un valor favorable, necesitarían encontrar entradas que hacheen a su deseado (lo cual es difícil si usamos una función de hash resistente a colisiones).
¡Pero cambiar mensajes anteriores afecta todos los desafíos posteriores! Así que necesitarían encontrar una transcripción completa donde todos los desafíos funcionen a su favor. Esto requiere encontrar no una, sino múltiples colisiones de hash o preimágenes, y esto es extremadamente difícil. ¡Tanto, que es inviable para el probador hacer trampa con esta estrategia!
Por último, incluyendo la entrada inicial (en nuestro caso anterior, ), hacemos que ni siquiera el resultado de la computación pueda cambiarse. Esto es súper importante, porque vinculamos la transcripción a lo que se está probando.
Estrictamente hablando, tendríamos que ser mucho más técnicos para probar formalmente la seguridad de la transformada. Es demasiado pronto para eso. ¡Llegaremos allí más adelante en el viaje!
La transformada de Fiat-Shamir es una de las ideas más elegantes y poderosas en criptografía. Una de las cosas más atractivas de ella es su universalidad: puede aplicarse a cualquier protocolo interactivo, no solo la verificación de la suma, siempre que haya una transcripción que podamos hacer hash.
El impacto práctico es enorme: las pruebas se convierten en artefactos portátiles que pueden almacenarse, y verificarse por cualquiera, en cualquier momento, en cualquier lugar.
¡Esta es la razón por la cual esencialmente cada sistema ZK moderno usa Fiat-Shamir, y es uno de los factores cruciales que hacen que la computación verificable y ZK sean prácticos en absoluto!
Resumen
¡Así que ahí lo tienes! ¡Hashes!
Estos pequeños desbloquean capacidades cruciales para nuestros sistemas de prueba. Están en todas partes, y proporcionan construcciones valiosas que hacen que nuestra criptografía simplemente funcione.
Todas las aplicaciones que vimos hoy se usan muy ampliamente en la práctica. Calculo que el artículo podría ser un poco más largo de lo anticipado, pero créeme: cada pieza importa para lo que viene después. ¡Nada se desperdiciará!
De especial importancia para nosotros es la transformada de Fiat-Shamir. Es seguro asumir que la aplicaremos a casi cualquier protocolo interactivo que diseñemos de aquí en adelante, incluso si no lo menciono explícitamente. ¡Así que solo mantén eso en el fondo de tus mentes!
Todavía tenemos bastantes protocolos por cubrir en la serie. Pero antes de hacer eso, vamos a necesitar comenzar a trabajar en otro concepto matemático crucial que nos acompañará el resto del viaje: grupos.
¡Ese será entonces nuestro próximo destino!


¿Te resultó útil este contenido?
Apoya a Frank Mangone enviando un café. Todos los ingresos van directamente al autor.