Blockchain 101: Más Allá de la Blockchain (Parte 2)
Esto es parte de una serie más larga de artículos sobre Blockchain. Si este es el primer artículo que encuentras, te recomiendo comenzar desde el inicio de la serie.
La última vez, nos desviamos un poco del camino y hablamos sobre Hedera, una red cuya estructura de datos fundamental para el consenso no es una Blockchain, sino un Hashgraph.
Realmente, Hashgraph es solo una palabra elegante para un Grafo Acíclico Dirigido (DAG), que es un tipo de grafo bien conocido y muy útil.
Pero el enfoque de Hedera también es disruptivo en el sentido de que descarta la idea de bloques, a favor de eventos. Así que supongo que podríamos preguntarnos si podría existir un punto medio: preservar bloques, pero usar un DAG en lugar de un Blockchain.
Bueno, técnicamente, una Blockchain ES un DAG, donde cada nodo tiene exactamente un ancestro. Supongo que sería más semánticamente preciso compararlo con una lista enlazada, sin embargo. ¿Una lista enlazada por hashes, quizás?
Dato curioso, esta fue en realidad una de las primeras preguntas que me hice cuando aprendía sobre sistemas Blockchain. Poco después fui entendiendo que esta era una hazaña técnica muy difícil por un par de razones fuertes, así que dejé de perseguir la idea en ese momento.
Avanzando unos años, resulta que la gente realmente está explorando el concepto DAG — pero tal vez no de la manera que había imaginado.
Así que hoy, quiero mostrarte uno de esos enfoques que usa un DAG con bloques como nodos (un BlockDAG, si se quiere), y cómo usan esto para evolucionar a un viejo amigo nuestro: Proof of Work.
¡Abróchate el cinturón y saltemos directamente a la acción!
Forks
Comenzaremos prácticamente de la misma manera que en el último artículo: volviendo a los fundamentos básicos.
Hemos hablado extensivamente sobre forks a lo largo de esta serie, pero ahora mismo, quiero que los revisemos desde un ángulo un poco diferente.
En Proof of Work, cuando dos mineros encuentran un bloque válido aproximadamente al mismo tiempo, la red se divide temporalmente en dos cadenas competidoras. Ambos bloques son perfectamente válidos, ya que contienen transacciones legítimas y representan trabajo computacional honesto. Pero eventualmente, una cadena será más larga, causando que la otra cadena (más corta) sea abandonada por la red.
Esta parte abandonada es desperdiciada. ¿Todo ese esfuerzo computacional puesto en los bloques descartados? Perdido.

Sip. Y aunque las transacciones eventualmente llegarán a otro bloque, no podemos evitar pensar que podría haber otra manera — una que evite tener que tirar todo ese valioso esfuerzo a la basura.
Esta es parte de la razón por la que surgieron otros mecanismos de consenso como un intento de crear algoritmos más eficientes, entre otras cosas.
Tales alternativas sí existen. Hay una postura diferente que podríamos tomar frente a las ineficiencias del Proof of Work tradicional. ¿Qué tal si no descartamos ningún bloque? ¿Qué tal si pudiéramos aprovechar toda la información contenida en ellos?
Desafíos
Por supuesto, esta no es una tarea simple.
Es importante considerar por qué el Proof of Work tradicional elige descartar cadenas competidoras más cortas. Y hay muy buena razón para eso.
Si diseñamos un sistema tal que preserve estos forks ramificados, entonces enfrentaremos varios problemas, a saber:
- ¿Cómo manejamos transacciones conflictivas a través de diferentes ramas?
- ¿Cómo prevenimos el doble gasto cuando la misma transacción podría aparecer en múltiples bloques?
- ¿Cómo mantenemos un estado consistente cuando estamos aceptando múltiples "verdades" simultáneamente?
- Pero más importante, ¿cómo ordenamos transacciones cuando están esparcidas a través de ramas?
La elección de Satoshi de tener una sola cadena ganadora simplemente evita todas estas complicaciones. Es una solución limpia y determinística — pero al costo de cantidades increíbles de computación desperdiciada.
Sin embargo, la tecnología ha evolucionado mucho desde entonces. Y los muchachos de Kaspa se propusieron preservar bloques y resolver todos esos desafíos al mismo tiempo.
Conoce a Kaspa
Kaspa es una Blockchain relativamente joven, con solo casi 4 años de edad al momento de escribir este artículo. Pero no dejes que su edad te engañe — está construido sobre algunas ideas seriamente sofisticadas.
Como Bitcoin, usa tanto el modelo UTXO como el consenso Proof of Work, así que estamos en terreno familiar aquí.
Pero a diferencia de Bitcoin, que produce un bloque cada 10 minutos, Kaspa genera un bloque por segundo. Sí, leíste bien — un bloque por segundo, usando Proof of Work.
Con las últimas actualizaciones, creo que es incluso más de un bloque por segundo, en realidad.
Y sí, sé lo que estás pensando. Se siente extraño. La esencia de Proof of Work es que encontrar un nuevo bloque toma tiempo y esfuerzo. Así que es natural preguntarnos cómo demonios esto no termina siendo un caos completo.
El Protocolo GHOSTDAG
Para hacer que las cosas funcionen, la gente de Kaspa ideó un algoritmo de consenso que llamaron el protocolo GHOSTDAG.

GHOST significa Greedy Heaviest Observed Sub-Tree (Árbol Subordinado Observado Más Pesado Codicioso). No creo que sea necesariamente fácil entender de qué se trata solo por ese acrónimo. Así que para aclarar, es esencialmente una manera de dar mecanismos de preferencia para la selección de forks, eligiendo el "más pesado", usualmente en términos de trabajo computacional. ¡Esto debería sonar familiar!
Y DAG, bueno... ¡Ya sabes qué significa!
Para darte una idea aproximada antes de entrar en los detalles, lo que sucede es que cada bloque válido individual se preserva, pero los bloques no se consideran iguales cuando se trata del ordenamiento de transacciones. Esa es realmente la salsa secreta en pocas palabras.
Pero, ¿cómo funciona esto? Primero, los bloques en Kaspa pueden referenciar múltiples bloques padre.
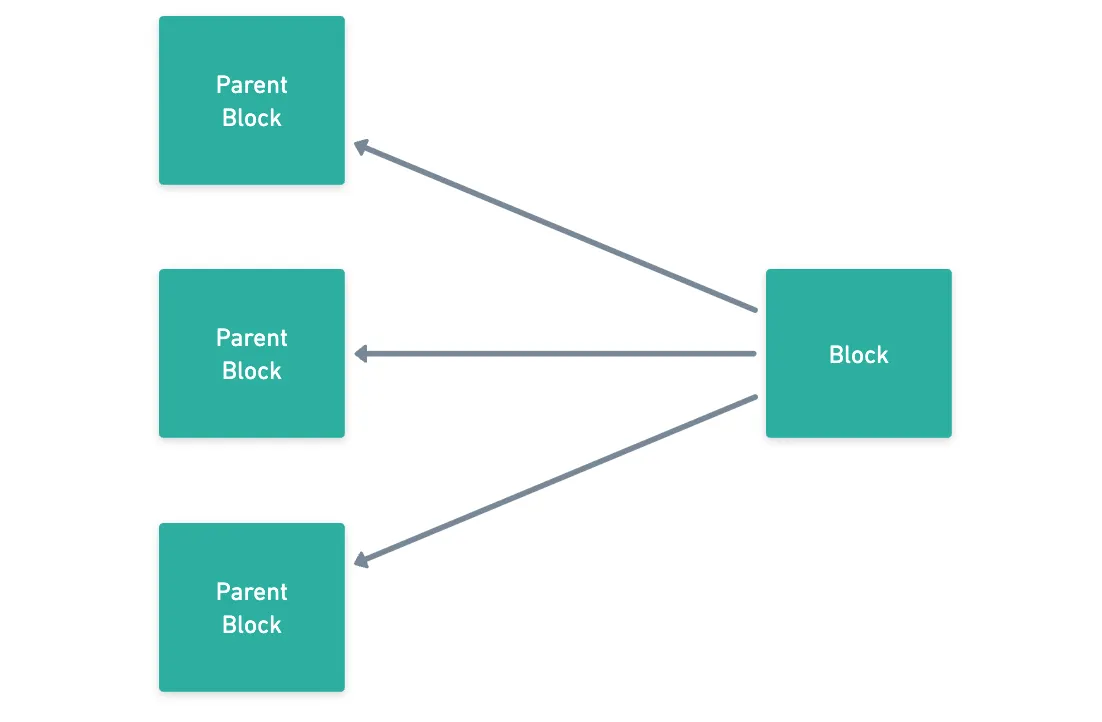
Esto por supuesto resulta en una estructura tipo red, que termina siendo nuestro DAG. Y como puedes imaginar, esto realmente no logra nada por sí solo, aparte de crear un desorden más grande de lo usual.
Sin embargo, las cosas comienzan a tener sentido una vez que aplicamos la regla GHOST. Esto está en el corazón mismo del asunto, así que vamos a desarmarlo paso a paso.
GHOST
Ahora tenemos un DAG lleno de bloques, y lo que necesitamos es una manera de determinar qué transacciones realmente se ejecutan, y en qué orden. Y no podemos simplemente ejecutar todo — eso llevaría a conflictos, doble gasto, y todo tipo de problemas. No exactamente el tipo de sistema que nos interesa.

GHOST resuelve esto introduciendo el concepto de una cadena seleccionada, que es un subgrafo lineal (así que una cadena) dentro del DAG.
Piensa en ello como encontrar la autopista principal en una red de carreteras altamente compleja.
Digamos que poseemos el estado actual de la red, en la forma de un DAG gigante. Para determinar la cadena seleccionada, seguiríamos estos pasos:
- Comenzar desde un bloque en la punta (o final) del DAG. En otras palabras, uno de los bloques más recientes.
- Luego, atravesar el DAG hacia atrás a través de todos los caminos posibles determinados por referencias padre, hasta llegar al bloque Génesis (¡el primer bloque!).
- Calcular el peso total de dichos caminos, y elegir el más pesado.
- La punta del DAG que tiene el subDAG más pesado será parte de la cadena seleccionada.
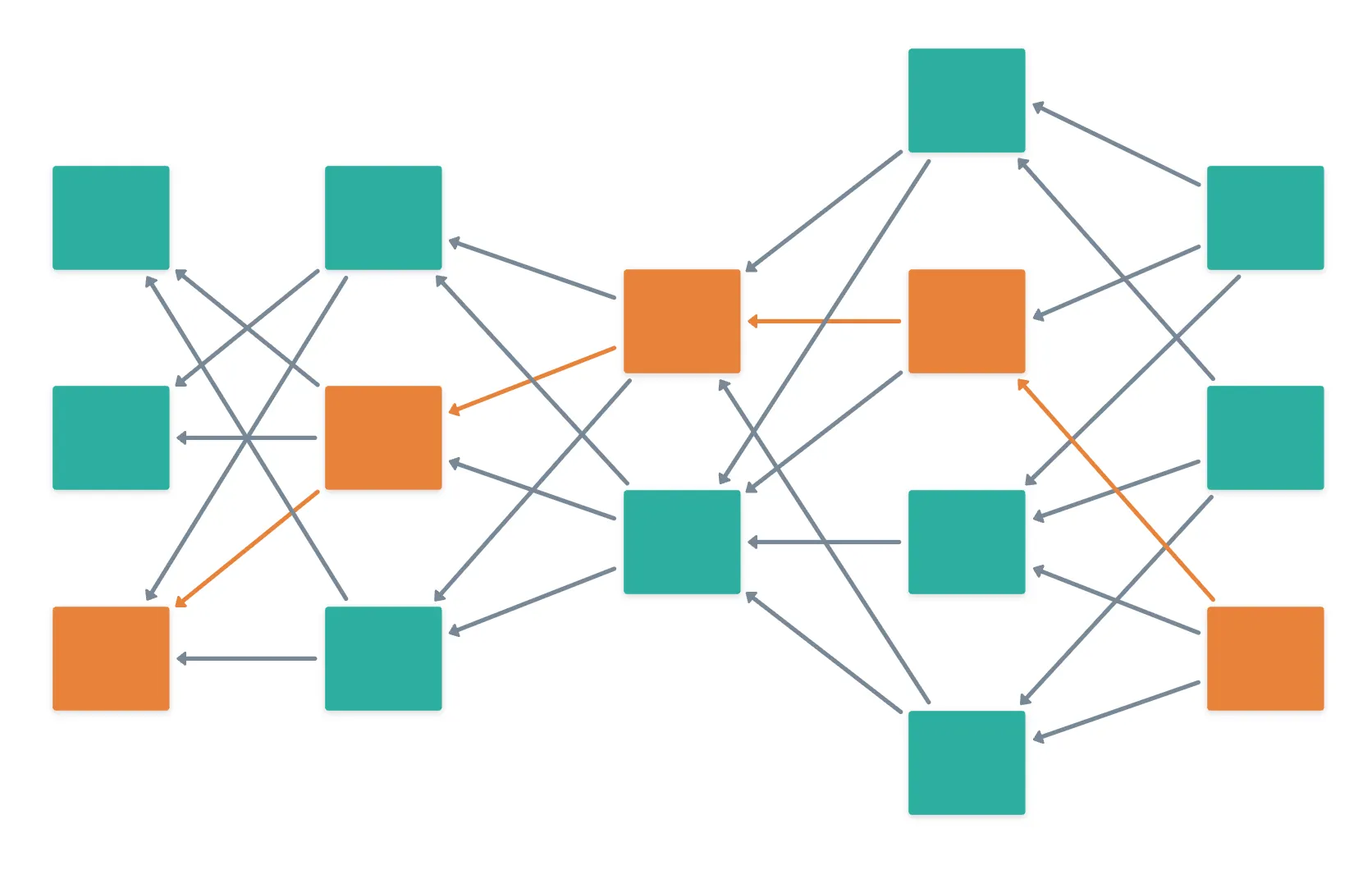
Bien, eso fue seguramente un montón. Y como se describe, prácticamente inviable. Así que vamos a desempacar un poco, ¿de acuerdo?
Peso del Bloque
Primero, ¿qué deberíamos entender por subDAG más pesado? ¿Cómo medimos el trabajo acumulado? Y en esa misma línea, ¿cómo medimos el trabajo gastado en un bloque individual?
Ya sabemos que minar un bloque se trata de encontrar algún nonce que produzca un hash del bloque que cumpla alguna condición especial. Por ejemplo, podríamos requerir que los primeros 6 dígitos de la representación binaria del hash sean unos, como esto:
![]()
![]() 1111110000000010011110010000110001101010011000010100101110100011001101001101000110101101010010100001100000110101001101110011011111100100110010100110011010011100100111100101100110100000100000101100001101010011001100010000110110100000101010011100100010010010
1111110000000010011110010000110001101010011000010100101110100011001101001101000110101101010010100001100000110101001101110011011111100100110010100110011010011100100111100101100110100000100000101100001101010011001100010000110110100000101010011100100010010010![]()
![]()
Dato curioso: ese es el SHA-256 de la cadena "Kaspa GHOSTDAG consensus mechanism". Tuve que probar con inputs por un rato — ¡un testimonio de que este es un problema no trivial de resolver!
Normalmente, sin embargo, lo que hacemos es interpretar el hash como un entero positivo, y simplemente verificar que su valor esté por debajo de algún umbral. Esto es muy simple de verificar, y de hecho, este umbral tiene un nombre: se llama el objetivo de dificultad de los bloques.
Cuanto más bajo el objetivo de dificultad, más trabajo necesitas poner para encontrar un bloque válido. Lo cual, en otras palabras, significa que estos valores son inversamente proporcionales.
Genial — ahora tenemos una manera de medir trabajo. ¿Qué sigue?
Peso del SubDAG
Como se adelantó anteriormente, el siguiente paso implica calcular el peso acumulado de subDAGs, para todas las puntas del DAG.
La razón por la que hacemos esto es porque aún necesitamos una fuente única de verdad: necesitamos derivar una historia de eventos de nuestro DAG que tenga sentido, y que evite conflictos y doble gasto.
Hacemos esto asignando una especie de puntuación a cada cadena posible, y la métrica que usamos es peso acumulado, que es solo la suma de los pesos individuales de bloques en un solo subDAG (o camino, para ser más preciso).
Si quieres una perspectiva más matemática, lo que estamos haciendo es derivar un ordenamiento topológico del conjunto de todos los subDAGs posibles asociados con las puntas, lo que nos permite seleccionar el supremo de la topología.
O en palabras simple: ¡tenemos un ordenamiento total de bloques, basado en peso acumulado!
Cuando lo ponemos todo junto, la consecuencia termina siendo la misma que en el Proof of Work tradicional: la cadena con más trabajo aún gana. Sin embargo, en este caso cada bloque individual puede contribuir al cálculo del peso. En este sentido, podríamos decir que ningún trabajo se desperdicia realmente.
¡Y eso es prácticamente la mayor parte! Hemos obtenido una manera determinística de determinar la cadena seleccionada, y esta será la que interpretemos como la historia de eventos en la red.
Es importante que nos detengamos aquí y nos enfoquemos en un pequeño detalle. Si tuviéramos que hacer este cálculo de subDAG para cada nuevo bloque individual, esto simplemente se convertiría en un proceso inviable, debido a la pura escala del DAG creciente. ¡Así que es absolutamente necesario que el algoritmo almacene en caché los pesos de los caminos que llevan al Génesis. ¡Esto es clave para el éxito de la estrategia!
Supongo que hay una pequeña pieza restante por resolver: ¿qué pasa con todas esas transacciones en los bloques no seleccionados? ¿Podríamos usarlas de alguna manera?
Bloques No Seleccionados
Recuerda, no queremos tirar estos bloques — son trabajo perfectamente válido, aún parte del DAG, y contribuyen a la seguridad general.
Y aquí, GHOSTDAG hace algo realmente inteligente: ¡procesa todas las transacciones en bloques no seleccionados también, siempre que no entren en conflicto con las del camino seleccionado!

De hecho, va incluso más allá: si dos transacciones entran en conflicto entre dos bloques no seleccionados, simplemente procesa la transacción del bloque que viene primero en el ordenamiento total. Porque recuerda — tenemos una manera de ordenar bloques por su trabajo acumulado.
¡Esencialmente, tenemos una manera de ordenar cada bloque individual en el DAG!
De esta manera, cada minero puede obtener una recompensa por su trabajo, y la mayoría de sus transacciones aún llegan a incluirse en la historia general.
Además, si asumimos que la mayoría de bloques en la misma altura tendrán transacciones no conflictivas (similar al enfoque de Aptos), entonces algo hermoso sucede: ¡la mayoría de transacciones en bloques minados pueden ser procesadas!
Y solo en el escenario extremo de que cada transacción individual en bloques no seleccionados entre en conflicto con la cadena seleccionada, efectivamente estaríamos ejecutando solo los bloques en la cadena seleccionada — así que vuelve al comportamiento de una Blockchain.
¿Qué tan genial es eso?
Resumen
No sé tú, pero encuentro esto verdaderamente sensacional.
Al alejarnos de la estructura Blockchain, aparentemente podemos obtener lo mejor de Proof of Work. GHOSTDAG realmente tiene algunos beneficios geniales, tales como:
- No se desperdicia trabajo, y cada bloque válido contribuye tanto a la seguridad como a la historia de la red,
- Las transacciones están claramente ordenadas, todo el tiempo,
- Y un rendimiento masivo, porque múltiples bloques pueden ser procesados simultáneamente.
Todo esto siguiendo el mismo principio de siempre: la cadena con más trabajo aún gana.
¡Pero con un giro!
Así que ahí lo tienes. Dos protocolos usando DAGs de maneras muy diferentes, pero mayormente reemplazando la estructura Blockchain.
Kaspa y Hedera no están solos, sin embargo. Algunos otros protocolos como Taraxa o BlockDAG (lo cual es interesante, porque es como llamar a una Blockchain "Blockchain") también están probando suerte con DAGs.
Honestamente no sé si esto será el futuro o no, pero lo que me gusta es que el espacio Blockchain está totalmente lleno de ideas geniales e innovadoras, constantemente empujando los límites de lo que es posible.
¡Y en mi humilde opinión, eso es lo que lo hace tan atractivo!
Dicho esto, el próximo destino en nuestro viaje nos llevará de vuelta a terrenos familiares, ya que exploraremos otra Blockchain. Ya sabes, sin estructuras subyacentes locas. Sin embargo, esta próxima Blockchain trae ideas muy geniales a la mesa, y es quizás diferente de lo que hemos visto hasta ahora.
Estoy hablando de un favorito personal: Polkadot. ¡Y comenzaremos a desarmarlo en el próximo artículo!


¿Te resultó útil este contenido?
Apoya a Frank Mangone enviando un café. Todos los ingresos van directamente al autor.