WTF es el Internet
Supongo que este artículo puede parecer un poco fuera de lo común. Así que para darles algo de contexto, quiero empezar esto con una pequeña historia.
Mi primer acercamiento a la programación fue hacer juegos simples en Flash, usando ActionScript.
Apuesto a que algunos de ustedes podrían recordar esos buenos viejos tiempos.
No había tenido ninguna educación formal en ciencias de la computación en ese momento, así que cuando probé suerte con el desarrollo web - que no era tan fácil hace 20 años como lo es hoy -, encontré muchas cosas difíciles de entender. En particular, no entendía muy bien cómo funcionaba el Internet.
Pero terminé enfocándome en la parte del desarrollo, sin prestar demasiada atención a lo que pasaba en el fondo. Porque carajo, ¿por qué me importa cómo funciona el Internet, si solo estoy tratando de construir una página web?
Avanzando unos 15 años, decido cambiar mi carrera profesional al desarrollo de software - de nuevo, como muchas personas han hecho en el pasado reciente. Lo que encontré fue que tenía muchas preguntas e inseguridades.
Ya saben, el caso típico del síndrome del impostor.
Si iba a tener éxito en este nuevo trabajo, necesitaba entender los principios básicos del desarrollo de software. Y aquí estaba yo, otra vez, preguntándome cómo carajos funcionaba el Internet, y cuánto necesitaba saber para convertirme en un buen profesional.
Mi intuición me dice que algunos de ustedes podrían sentirse identificados con esta experiencia personal.
Por lo tanto, este artículo es para aquellos de ustedes que todavía están un poco confundidos sobre este tema, y quizás quieren llenar algunos baches en su conocimiento.
Y solo puedo hablar por mí mismo acá, pero sé que me habría ayudado leer esto hace un par de años.
¡Así que sí! Creo que hay mucho para ganar al explicar un poco lo que pasa detrás de escena - no solo para entender los procesos que ocurren cuando visitamos un sitio web, sino también para evaluar correctamente los desafíos y problemas que podemos encontrar al construir software.
¡Vamos!
Primeros Pasos
Allá por la década de 1960, las ciencias de la computación todavía estaban en su infancia. Las computadoras no eran nada como los dispositivos pequeños pero súper poderosos que ahora podemos sostener en la palma de nuestras manos. Más bien, eran estas carcasas voluminosas que nunca esperarías encontrar en ningún hogar normal.

El acceso a estas máquinas era por supuesto limitado. Y el tiempo de computación era un nuevo recurso atractivo, principalmente para investigadores. El nombre del juego era la capacidad de hacer tiempo compartido: permitir que muchas tareas fueran ejecutadas por una sola computadora al mismo tiempo (concurrentemente).
El equivalente computacional de hacer multitasking.
Sin embargo, no había una forma definida de ejecutar tareas a distancia. Esto puede parecer difícil de creer porque hoy en día, podemos tener chats en tiempo real con personas al otro lado del mundo - ¡pero no siempre fue así!
Entonces, uno de los grandes temas de investigación en ese momento era cómo transmitir instrucciones de ejecución a largas distancias. El mundo ya había visto el telégrafo para ese entonces - así que no era una hazaña inalcanzable.
Era más una cuestión de eficiencia. En otras palabras:
¿Cómo envías información eficientemente por largas distancias entre computadoras?
Esta era la pregunta a responder para los investigadores de la época.
Conmutación de Paquetes
Igual que el telégrafo, otra invención que estaba muy bien establecida en ese momento era el teléfono. Las redes telefónicas tradicionales usaban lo que se llama conmutación de circuitos: una conexión física dedicada se creaba entre dos puntos durante toda la duración de una comunicación.
Eso es exactamente lo que vemos en las películas contemporáneas - personas conectando cables en tableros de conmutación bajo demanda.

Esto funcionaba bien para llamadas de voz, pero era muy ineficiente para comunicaciones de computadora, que tienden a ocurrir en ráfagas.
Cuando cargas tu feed de Instagram, normalmente haces una carga inicial "pesada", y luego la app se vuelve "inactiva" y espera por tus interacciones antes de solicitar más información. Aunque algunas cosas pueden pasar en el fondo, el flujo general funciona más o menos así.
No es muy eficiente tener que crear una conexión de cable dedicada para cada ráfaga de información. Se necesitaba un enfoque diferente.
La solución vino al invertir el problema: construyes una autopista estática de conexiones entre diferentes dispositivos, y en lugar de que la información vaya por un camino directo, le permites tomar cualquier ruta - ¡mientras llegue a su destino, deberíamos estar bien!
Igual que Amazon entregando tus cosas - tienen el origen del paquete, el destino, y deciden qué ruta tomar por ti.

Esto es lo que se llama conmutación de paquetes. Era un concepto revolucionario en ese entonces, desarrollado independientemente por científicos computacionales como Paul Baran y Donald Davies a principios de los años 1960.
Los datos se dividen en pequeños trozos, llamados paquetes, cada uno conteniendo información sobre de dónde vino y hacia dónde se dirige. Estos paquetes viajan a través de una red, tomando diferentes rutas, y luego se reensamblan en su destino.
Genial, ¿verdad?
El único problema es que necesitamos una red - las autopistas por las cuales estos paquetes viajan. ¡Y esa infraestructura realmente no existía todavía!
ARPANET
Afortunadamente para nosotros, esta idea de conmutación de paquetes no se archivó. En su lugar, se creó la infraestructura requerida para ponerla en buen uso.
En 1969, la Agencia de Proyectos de Investigación Avanzada (ARPA por sus siglas en inglés) creó la primera red de conmutación de paquetes, y la llamó (redoble de tambores por favor) ARPANET.
Sí... Los ingenieros no somos conocidos por ser las personas más creativas.
Inicialmente, solo conectaba cuatro instituciones de investigación, pero esto fue suficiente para demostrar que la tecnología de conmutación de paquetes funcionaba.
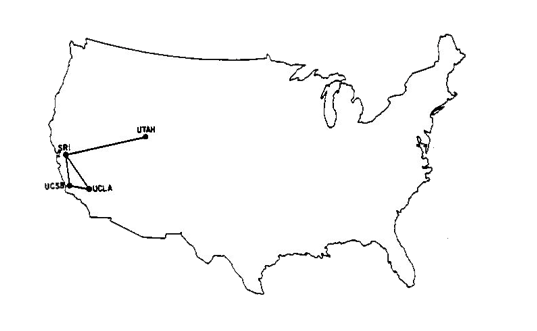
Durante la siguiente década, más y más instituciones comenzaron a conectarse a ARPANET. Lento pero seguro, la red comenzó a crecer.
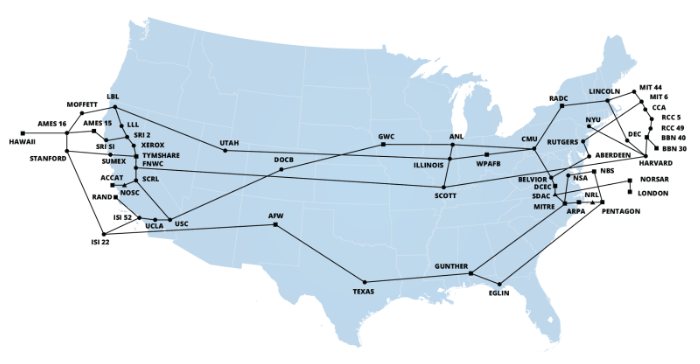
Una red más grande era bastante genial - porque permitía comunicación con muchas más computadoras. Sin embargo, esto vino acoplado con otro problema.
Verán, con solo cuatro instituciones que estaban relativamente cerca en términos de distancia, los investigadores podían ponerse de acuerdo sobre cómo identificarse entre sí, y el formato de los mensajes que intercambiaban. A medida que se agregaron computadoras e instituciones a la red, necesitaban ser identificables por otras computadoras existentes, y necesitaban seguir algunas reglas para enviar correctamente paquetes de una ubicación a otra (enrutamiento de paquetes), y para que otras computadoras entendieran sus mensajes.
¿Pero qué reglas? ¿Quién define cómo hacer las cosas?
Para que todo no se volviera caótico, se necesitaba algún tipo de estándar. Un conjunto bien definido de reglas a seguir. Un protocolo.
Las Reglas del Internet
Pregunta: ¿qué creen que pasa cuando navegan a un sitio web en su navegador?
Bueno, para ser justos, pasan bastantes cosas - pero lo más importante: su navegador está trayendo un montón de archivos de otra computadora en algún lugar del mundo.
Es común hablar de "la nube" hoy en día, pero por supuesto, los sitios web no están simplemente flotando en el éter - son una combinación de archivos almacenados en algún lugar, entregados precisamente a tu pantalla.
Esto significa al menos dos cosas: que necesitamos identificar correctamente tanto las computadoras fuente como destino, y que necesitamos una forma de asegurar que paquetes o datagramas sean efectivamente enviados desde la fuente, y hacia nuestras pantallas. Y así es como surgió el Protocolo de Internet.
El Protocolo de Internet
Piensen en una oficina postal entregando cartas. Obviamente, esperan que cada carta tenga una dirección en algún tipo de formato común, como . Otras combinaciones de cosas podrían sentirse raras, y el servicio de entrega realmente no sabría qué hacer con ellas.
Empecemos con la parte simple - identificación. Igual que las direcciones reales, las direcciones IP se convirtieron en la forma de identificar computadoras que se conectarían a través de la red.
El tipo más común de dirección es la IPv4, que se ve así:
172.16.254.1
Lo que estamos viendo es solo un número de 32 bits, dividido en 4 secciones de 8 bits (un byte), separadas con puntos, y en decimal.
Esta es simplemente una forma bonita y conveniente de representar un número entre y .
Ese número () en realidad no es tan grande. Son aproximadamente 4 mil millones. Análisis estadísticos y de mercado estiman que el número de computadoras y dispositivos personales excede esa marca, lo cual es bastante alarmante, porque significaría que las IPs no son únicas!
Quiero decir, esto es de esperarse de un estándar definido en 1983 - era difícil prever el nivel de adopción masiva en ese momento, supongo.
Aunque hay algunas soluciones temporales - como Traducción de Direcciones de Red (NAT), que permite que múltiples dispositivos compartan una sola dirección IP -, esta limitación llevó al desarrollo de IPv6.
Las direcciones IPv6 se ven así:
2001:0db8:85a3:0000:0000:8a2e:0370:7334

Eso se ve mucho menos amigable que IPv4 - pero bajo la superficie, es solo otra forma de presentar 128 bits. Y existe un gran total de aproximadamente 340 undecillones de direcciones únicas (eso es 340 seguido de 36 ceros).
Para poner eso en perspectiva, podríamos asignar una dirección IP a cada átomo en la superficie de la Tierra y aún tener muchas IPs sobrantes.
La adopción de IPv6 ha sido realmente lenta, y hoy, tanto IPv4 como IPv6 coexisten. Sí, actualizar el internet es difícil. ¿Quién lo habría pensado?
Enrutamiento
Ahora que tenemos nuestras computadoras identificadas, necesitamos asegurar que los paquetes lleguen a su destino. Pero recuerden, el Internet es esencialmente un grafo de sistemas conectados (una red), y nuestros paquetes probablemente necesitan hacer unas cuantas paradas en el camino.
Aquí es donde el enrutamiento IP entra en escena. El enrutamiento es en realidad bastante simple: es como pedir direcciones. Cada vez que un paquete llega a un router, básicamente pregunta: "¿Cómo llego a este destino?".
Los routers son computadoras especializadas cuyo trabajo principal es dirigir tráfico. Intersecciones en nuestra autopista del internet, con esas grandes señales verdes diciéndole a los paquetes qué salida tomar.

Su router casero es donde su red personal se encuentra con el Internet más amplio - la rampa de acceso a la autopista de la información, por así decirlo.
Se requieren dos ingredientes para que esto funcione:
- Este router necesita poder entender hacia dónde se dirige el paquete, y
- También necesita saber hacia dónde dirigirlo.
La primera parte es fácil: de nuevo, dependemos de la estandarización, y tenemos nuestros paquetes conteniendo un encabezado con información crucial - como de dónde viene, hacia dónde se dirige, la longitud del paquete, y algunas cosas más.
Todo empaquetado en lo que llamamos un paquete IP.
Es la segunda parte la que no es tan directa.
Verán, si cada router tuviera que mantener una lista de todos los otros routers y con quién están conectados, nos meteríamos en problemas rápidamente. Para empezar, la cantidad pura de información (de todas las redes en el mundo) requeriría demasiada memoria.
Sin mencionar que esta lista es altamente dinámica - cambia todo el tiempo. Mantener cada router actualizado todo el tiempo simplemente no sería posible: el Internet gastaría más tiempo transmitiendo información sobre cambios de red que realmente moviendo datos.
¿Qué hacemos entonces?

El Internet usa un enfoque inteligente: enrutamiento jerárquico. Un ejemplo ayudará aquí:
Imaginen que quieren enviar una carta desde su ciudad natal a alguien en Japón.
Su oficina postal local no necesita saber el diseño exacto de cada calle en Tokio. Solo necesita saber enviar correo internacional a una instalación de clasificación regional, que sabe enviarlo al hub internacional, que sabe enviarlo a Japón, y así sucesivamente.
Los routers funcionan de manera similar. Mantienen tablas de enrutamiento que contienen información sobre:
- Redes a las que están directamente conectados (conexiones vecinas)
- Qué router vecino entregar paquetes para destinos distantes
Por ejemplo, su router casero no sabe cómo llegar a los servidores de Google directamente. Solo sabe enviar todo el tráfico "no-local" al router de su Proveedor de Servicios de Internet (ISP). El router de su ISP podría saber enviar tráfico de Google hacia un intercambio de internet principal específico. Y así sucesivamente, hasta que el paquete llegue a su destino.
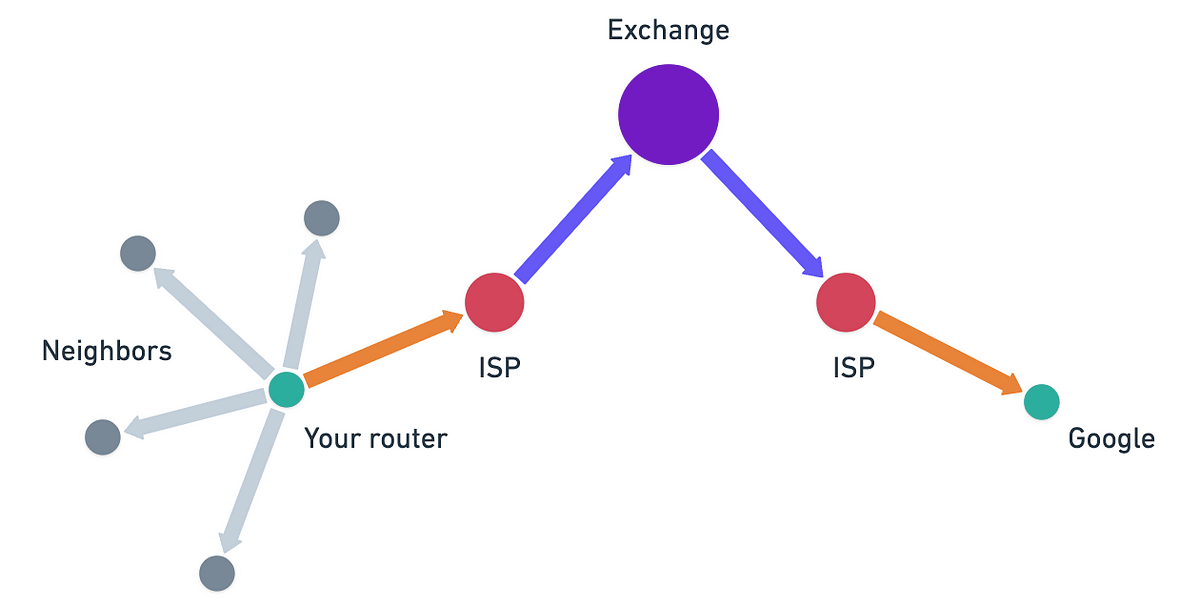
Esto no solo es eficiente, sino que también es un modelo muy resistente. Cuando alguna conexión falla en algún lugar, solo los routers en esa área necesitan encontrar caminos alternativos y compartir esa información con sus vecinos. ¡El resto del Internet no se ve muy afectado por estas interrupciones locales!
Interpretando Información
Bien, ahora sabemos cómo los paquetes van de un lugar a otro. Pero recuerden - nuestros datos originales se dividieron en piezas más pequeñas, se empaquetaron en estos paquetes, y se enviaron en su camino.
Así, el receptor no obtendrá todos los datos en una sola entrega ordenada, sino que obtendrá un lío de trozos que necesitan organizar de alguna manera en contenido significativo.
Cuando cargas una página web, querrías que todos los paquetes se reconstruyan de tal manera que la página web se vea bien, ¡y no el mejor esfuerzo de alguien que apenas está aprendiendo CSS!

¿Cómo hacen eso?
Respuesta corta: necesitamos más protocolos.
Hay dos protocolos de transporte principales en este nivel: el Protocolo de Datagramas de Usuario (UDP), y el Protocolo de Control de Transmisión (TCP). Nos enfocaremos en el último primero, ya que es el más ampliamente usado.
Protocolo de Control de Transmisión
Ordenar paquetes toma un poco de trabajo extra. Lo que TCP propone es esto:
- Establecer una conexión inicial: como tocar la puerta del receptor, para ver si está en casa, y listo para recibir paquetes.
- Numerar los paquetes: cada paquete recibe un número de paquete único e incremental, para que puedan ser puestos en el orden correcto por el receptor.
- Recibir reconocimiento: el receptor le dice al emisor "sí, obtuve el paquete #47" para que el emisor sepa que llegó.
- Retransmisión de paquetes perdidos: Si el paquete #47 nunca recibe confirmación de ser recibido, el emisor intentará enviarlo de nuevo.
- Control de flujo: TCP previene que el emisor abrume al receptor con demasiados datos a la vez.
Con estas reglas relativamente simples, aseguramos una entrega confiable y ordenada de datos. No más fotos de gatos a medio cargar. Genial.
Por supuesto, esta confiabilidad no es gratis - TCP tiene overhead. Reconocer, numerar, y retransmitir toman tiempo y ancho de banda.
Para algunas aplicaciones como streaming de video o juegos en línea, este overhead puede convertirse en un cuello de botella crítico - es mejor obtener nuevos datos rápidamente, en lugar de esperar que los datos viejos sean retransmitidos. Es en estas situaciones que UDP realmente brilla: usa una estrategia de "disparar y olvidar", que es más rápida, pero menos confiable.
Juntándolo Todo
Para empezar a atar cabos, volvamos a nuestra pregunta original: ¿qué pasa cuando navegan a un sitio web en su navegador?
- Tu navegador determina la dirección IP del servidor con el que comunicarse
- A través de TCP, se establece una conexión confiable con ese servidor
- Tu navegador envía una solicitud sobre esa conexión TCP
- El servidor responde con los datos de la página web
- TCP asegura que todos los datos lleguen correctamente y en orden
- Tu navegador renderiza la página
Lo que es bastante alucinante es que todos estos pasos típicamente pasan en milisegundos, gracias a décadas de refinamiento de ingeniería.
He simplificado algunos detalles - pero estoy dispuesto a apostar que todavía tienen una pregunta persistente después de leer eso.
¿Cómo sabe su navegador a qué dirección IP conectarse, cuando escribieron "google.com"?
El Sistema de Nombres de Dominio
Correcto - escriben "google.com" o "twitter.com" o "stackoverflow.com" - no alguna secuencia rara de dígitos. Pero TCP solo entiende direcciones IP, así que necesitamos una forma de mapear esos dominios a direcciones IP.
Podríamos pensar en estos dominios como alias - pero el problema es que todos deberían estar de acuerdo en el mapeo de alias a dirección IP. ¿Cómo aseguramos que este mapeo sea consistente a través del vasto Internet?
Esto es lo que resuelve el Sistema de Nombres de Dominio (DNS).
A.k.a. la guía telefónica del Internet.
Igual que nuestro problema de enrutamiento anterior, no es factible mantener este mapeo en cada computadora, debido a su tamaño, y qué tan seguido necesita ser actualizado.
Por lo tanto, el DNS también funciona de manera jerárquica, distribuida. Primero verificas el caché de tu computadora - una pequeña lista de conversiones conocidas de dirección IP a dominio. Si no se encuentra coincidencia, el siguiente paso es preguntarle a tu ISP. Y si no saben, escalan la consulta a lo que se llama un servidor de nombres raíz (también conocido simplemente como servidores raíz).
¡Hay un gran total de 13 servidores raíz "principales" en todo el mundo!
Estos a su vez preguntan a los servidores .com, quienes preguntan a servidores autoritativos más pequeños, quienes finalmente responden con "esta es la dirección IP para google.com".
Y una vez que tu ISP aprende la dirección IP correcta, la recuerda (¡la guarda en caché!) para consultas posteriores. ¡Y tu computadora también!
En general, es un sistema muy inteligente.
Hay más que esto que esta breve explicación - DNS puede configurarse de varias maneras a través del uso de diferentes registros DNS, y permiten trucos geniales como:
- balanceador de carga: resolver un dominio a diferentes direcciones IP.
- redundancia: múltiples IPs devueltas para el mismo dominio.
Sin embargo, viene con algunas fallas: porque fue diseñado en una era de más "confianza", pasó por alto algunos posibles ataques. En particular, el envenenamiento DNS puede redirigir usuarios a sitios maliciosos, y las caídas de DNS pueden efectivamente hacer que grandes porciones del Internet sean inalcanzables.
Resumen
Si esto se sintió como mucha información, es porque lo es.
Después de todo, el Internet es un sistema muy complejo e intrincado. Incluso después de todas las cosas que hemos cubierto, todavía hay mucho más que aprender. Por ejemplo:
- ¿Cómo se transmite exactamente la información en el sentido físico?
- ¿Qué es HTTP, y cómo solicitan y reciben realmente las páginas web los navegadores web?
- ¿Cómo funciona la seguridad del Internet?
- ¿Qué pasa (y qué podemos hacer) cuando las cosas van mal?
- ¿Qué depara el futuro para el Internet?
Es un tema bastante involucrado - y como mencioné al comienzo del artículo, dependiendo de lo que hagan o lo que estén construyendo, realmente no necesitan saber todos los detalles.
Aún así, creo firmemente de que hay mucho para ganar al tratar de entender estos sistemas complejos, ya que muestran enfoques inteligentes para la resolución de problemas que pueden ser útiles en otras situaciones.
Y así, la próxima vez que naveguen sin esfuerzo a su sitio web favorito, recuerden que hay una infraestructura global completa, trabajando en meros milisegundos para conseguirles sus preciados artículos diarios.
Bastante genial que toda esta complejidad esté oculta detrás de algo tan simple como escribir una URL, ¿verdad?


¿Te resultó útil este contenido?
Apoya a Frank Mangone enviando un café. Todos los ingresos van directamente al autor.