Blockchain 101: Manejo de Datos
Este artículo es parte de una serie más larga sobre Blockchain. Si este es el primer artículo que encuentras, te recomiendo comenzar por el inicio de la serie.
La última vez que nos encontramos, dimos un breve recorrido por las aplicaciones de la tecnología ZK en Blockchain. Si hacemos memoria, había dos razones principales por las que ZK estaba encontrando su lugar en las Blockchains: verificación rápida y pruebas pequeñas.
La verificación rápida es fácil de entender. El rol de los validadores es — lo adivinaste — ¡validar bloques! Así que mientras más rápido puedan hacerlo, mejor será para el protocolo en general.
Esa es la teoría, al menos — hay algunas limitaciones a esto, como vimos en la entrega anterior!
Pero ¿por qué exactamente serían importantes las pruebas pequeñas? Bueno, esencialmente hay dos cosas de las que deberíamos preocuparnos. Y como pronto descubriremos, estos problemas nos catapultarán directamente al corazón de la discusión de hoy: Disponibilidad de Datos.
Así que comencemos la discusión de hoy tocando esta pregunta.
¿Café listo? ¡Vamos!
Datos en Blockchain
Hablemos de los ZK rollups por un segundo.
Como ya sabemos, los ZK rollups publican pruebas de sus transiciones de estado en su respectiva capa 1. Esto se hace, por supuesto, para evitar publicar su historial completo de transacciones. Pero ¿por qué importa esto?
Cualquier cosa que se publique en la Blockchain de capa 1 necesitará ser verificada por los validadores. Y para esto, la información debe ser difundida, para que cada validador tenga toda la información que necesita para inspeccionar y validar.
Así, el primer problema viene en forma de comunicación eficiente: mientras más información tengan que compartir entre ellos, más lento será el consenso en general.
Esto es cierto para cualquier tipo de información que los validadores necesiten verificar. Y dado que la información está contenida en bloques, hay un equilibrio del que debemos ser conscientes:
![]()
![]() Cuánta información metemos en los bloques versus qué tan lenta será la red
Cuánta información metemos en los bloques versus qué tan lenta será la red![]()
![]()
Al diseñar una Blockchain, este es uno de los elementos clave de los que necesitamos preocuparnos. Para resolver el problema, las Blockchains en general imponen límites en el tamaño de los bloques para mantener sus tiempos de bloque consistentes.
Sería genial si esa fuera el final de la historia. Pero desafortunadamente, esto creó otro problema: escasez.

Espacio de Bloques
A medida que una Blockchain ve más y más tráfico, tendrá más transacciones que validar. Pero dado que los bloques tienen un espacio limitado, solo hay tanto que se puede procesar a la vez.
Entonces, ¿quién logra que sus transacciones sean incluidas? ¿Quién tendrá que esperar?
Bueno... ¿Qué tal si dejamos que eso se regule solo? Hacemos que las transacciones sean más caras cuando hay mucha demanda, para que no todos estén dispuestos a pagar, reduciendo así la cantidad de transacciones que necesitan ser procesadas.
¿Ves lo que pasó? Acabamos de ponerle un precio al Espacio de Bloques, y expusimos su precio a la lucha de oferta y demanda. Acabamos de crear un recurso escaso.
En otras palabras, publicar datos en una Blockchain no es gratis, ya que el espacio (más precisamente, memoria distribuida persistente) en estos entornos es escaso, porque necesita ser escaso para que la red no sea más lenta que un perezoso en un mal día.

En conjunto, estos factores son la razón por la que nos importa el tamaño de las pruebas: para pagar menos tarifas de red.
Este es el problema esencial de la Disponibilidad de Datos — un problema que, en su núcleo, surge de la necesidad de comunicación eficiente entre validadores.
Ahora, dadas estas restricciones, ¿qué podemos hacer al respecto?
Varias aproximaciones diferentes son posibles, dependiendo de qué tan profundo estemos dispuestos a ir. Comencemos simple.
Almacenamiento Fuera de Cadena
Abordemos primero el elefante en la habitación:
![]()
![]() ¿Necesitamos poner todo en la Blockchain?
¿Necesitamos poner todo en la Blockchain?![]()
![]()
Imagina que quieres adjuntar un JSON a alguna transacción, quizás conteniendo algunos metadatos importantes. Sabemos que esto es subóptimo desde una perspectiva de almacenamiento: los costos de transacción aumentarán mientras más datos queramos meter ahí.
Pero ¿por qué poner ese JSON en la Blockchain? La respuesta usual es transparencia: queremos que todos tengan acceso a esta información para que sea fácil de auditar.
Eso es completamente justo — pero realmente, no necesitamos almacenar toda la información en cadena para que sea auditable y transparente. Todo lo que necesitamos es una forma de usar la Blockchain para verificar que alguna información reclamada, almacenada en otro lugar, es correcta.
Los Hashes al Rescate
Afortunadamente, podemos recurrir a técnicas criptográficas simples para hacer esto.
El hashing es super útil en este sentido. Debido a sus propiedades, un hash de un documento funciona tanto como un identificador prácticamente único, como también una prueba sólida de que el documento original no ha sido alterado.
Con el hashing, es realmente fácil dividir el problema: solo almacena el documento en otro lugar, calcula su hash, y publica dicho hash en la Blockchain.
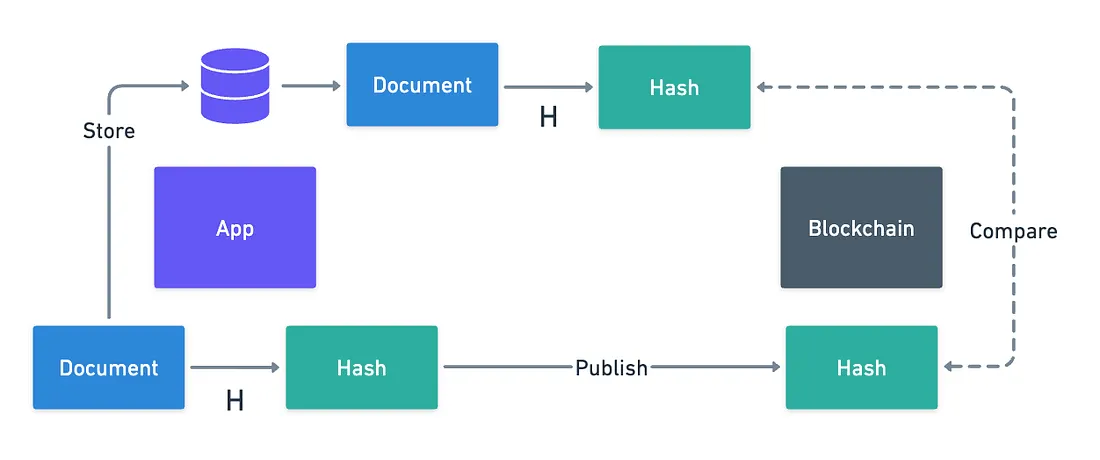
Fácil, ¿verdad? Excepto que hay un problema enorme: ¿qué pasa si los datos originales se pierden?
Las funciones de hashing son irreversibles por diseño, lo que significa que no deberíamos poder recuperar los datos originales del hash. Así que si los datos realmente se pierden, entonces no hay forma de recuperarlos — y nos quedamos con algún hash sin sentido permanentemente almacenado en la Blockchain.
Sí... No es ideal.
Dado que el hash no va a ningún lado, lo que podemos hacer es mejorar la forma en que almacenamos la información original. Y diablos, si confiamos en la descentralización para hacer que las Blockchains sean duraderas e inmutables... ¿Por qué no intentar algo similar con el almacenamiento fuera de cadena?
IPFS
Esta es exactamente la idea detrás de uno de los sistemas de almacenamiento fuera de cadena más populares: el Sistema de Archivos Interplanetario, o IPFS por sus siglas en inglés.

IPFS también es una red distribuida de nodos, cuyo único trabajo es almacenar datos. El contenido en sí está dirigido por contenido, con el hash del contenido funcionando también como su identificador. Esto asegura que cualquier dato que recuperes, independientemente de dónde lo obtengas, no ha sido alterado.
Puedes imaginar que diseñar tal sistema también viene con su propio conjunto de matices. Y tendrías razón.
Primero, intentemos imaginar dónde se almacenarían realmente los datos. ¿Cada nodo mantendrá una copia completa de cada elemento de almacenamiento? Eso parecería innecesario — podríamos distribuir la carga, y hacer que cada nodo almacene una fracción de los archivos. Mientras un nodo tenga tu archivo, la red podrá recuperarlo.
Se dice que un nodo único que almacena un archivo está anclando el archivo, en la jerga de sistemas de almacenamiento distribuido. Todo estará bien mientras al menos un nodo esté anclando tu archivo — pero si eso no sucede, entonces la información se perderá de todas formas.
Así que quizás entrarás en pánico un poco cuando diga esto, especialmente si has estado usando IPFS para almacenamiento permanente: IPFS no garantiza el anclaje de archivos.

Sí, lo que acabas de leer. IPFS es más adecuado para hacer que los datos estén temporalmente disponibles.
¡Pero no entres en pánico todavía!
Pinata
Pinata es esencialmente IPFS con esteroides.

Me encanta el logo.
Su objetivo es simple: asegurar que un archivo permanezca disponible en IPFS. Proporcionan anclaje como servicio, lo que en resumen significa que mientras les estés pagando, se asegurarán de que tu archivo siempre esté anclado en IPFS. Efectivamente, podemos pensar en Pinata como un conjunto de nodos IPFS que garantizan que nuestro archivo estará anclado para siempre — o al menos, mientras estemos pagando.
Tan bueno como suena esto... Hay una trampa. ¿Puedes adivinar cuál es?

Al usar Pinata, estás introduciendo una dependencia centralizada de vuelta en tu sistema. Así que si Pinata se cae, o simplemente decide dejar de anclar tus archivos, estás de vuelta al punto de partida. Además, estás confiando en que realmente mantengan su promesa — no hay nada que los detenga de desanclar tus archivos si deciden que tu contenido viola sus términos de servicio.
Ah, y por cierto, antes de que lo olvide: también está Arweave, que toma un enfoque diferente para el almacenamiento permanente. En lugar de requerir pago continuo como Pinata, Arweave usa un modelo de pago único por adelantado donde los usuarios pagan una vez por almacenamiento permanente de datos.
¡No quiero seguir metiendo cosas en este artículo, así que es solo otra cosa que tendrás que revisar por tu cuenta!
Ya sabes, los clásicos trade-offs. Para muchas aplicaciones, esto es completamente aceptable. Pero otras pueden requerir garantías más fuertes.
Lo que nos lleva al siguiente nivel de nuestra exploración.
Capas de Disponibilidad de Datos
Para ser justos, las soluciones que hemos visto hasta ahora son más que suficientes para muchos casos de uso — pero no podemos simplemente pasar por alto el hecho de que involucran algún tipo de compromiso.
Pero estamos pensando en soluciones fuera de la Blockchain misma. Aunque conocemos las razones para esto, es innegable que Blockchain está mejor equipada para resolver estos problemas que hemos encontrado en estos otros sistemas fuera de cadena — las Blockchains son persistentes, en contraste con IPFS, y también son resistentes a la censura y descentralizadas, en contraste con Pinata.
¿Qué tal si pudiéramos obtener lo mejor de ambos mundos? ¿No podríamos tener una red Blockchain diseñada para Disponibilidad de Datos en lugar de computación general?
La respuesta es sí. Y es exactamente lo que las Capas de Disponibilidad de Datos intentan resolver.
Celestia
Un ejemplo de una Blockchain que pone la Disponibilidad de Datos en el centro de su diseño es Celestia.

Como hemos mencionado antes, la mayoría de las Blockchains han sido construidas con esta mentalidad de solución todo-en-uno — pero hay valor en la especialización.
Para poner esto en perspectiva, ya hemos visto un caso donde la funcionalidad de Contratos Inteligentes fue eliminada de una Blockchain: Polkadot. ¡La idea es que al enfocarnos o especializarnos en algo, podemos intentar hacerlo mejor que si intentáramos hacer todo a la vez!
Celestia no está diseñada para ser una Blockchain de propósito general. Fue concebida para hacer una cosa muy bien: hacer que los datos estén disponibles. De esta manera, otras Blockchains pueden construir sobre esta disponibilidad de datos nativa, mientras resuelven cómo manejar la lógica en su extremo.
Lo que hace a Celestia particularmente atractiva desde un punto de vista técnico es que tienen una gran solución a un problema con el que muchas Blockchains han tenido dificultades para lidiar.
Muestreo de Disponibilidad de Datos
Siempre que un validador verifica un bloque, está claro que necesita acceso a la totalidad de su contenido. No queremos dejar nada al azar: todo necesita ser revisado a fondo. Así que necesitan descargar bloques completos.
Pero aquí hay una pregunta: ¿todos los que leen la Blockchain necesitan toda esta información? ¿Nos importa todo el contenido de los bloques, o principalmente nos importa el estado resultante?
Piensa en esto: la mayoría de los usuarios realmente no se preocupan por la mayoría de las transacciones en un bloque. Y a medida que los bloques se hacen más grandes, se vuelve impráctico para dichos usuarios verificar la cadena, como en verificar cada bloque.
Claro, pueden hacerlo, pero consumen ancho de banda, memoria y recursos, mientras que realmente no necesitan verificar todo.
Sería mucho mejor simplemente asegurar que los bloques verificados existan, y que su información esté disponible y accesible en caso de que realmente la necesites, ¿verdad?
Celestia resuelve esto con lo que se llama Muestreo de Disponibilidad de Datos (o DAS por sus siglas en inglés).
Básicamente, lo que proponen es codificar bloques de tal manera que usuarios individuales puedan simplemente descargar una pequeña porción de la información de un bloque, y garantizar que el resto de la información estará ahí si se consulta.
Y con suficientes fragmentos, puedes recuperar el bloque completo.
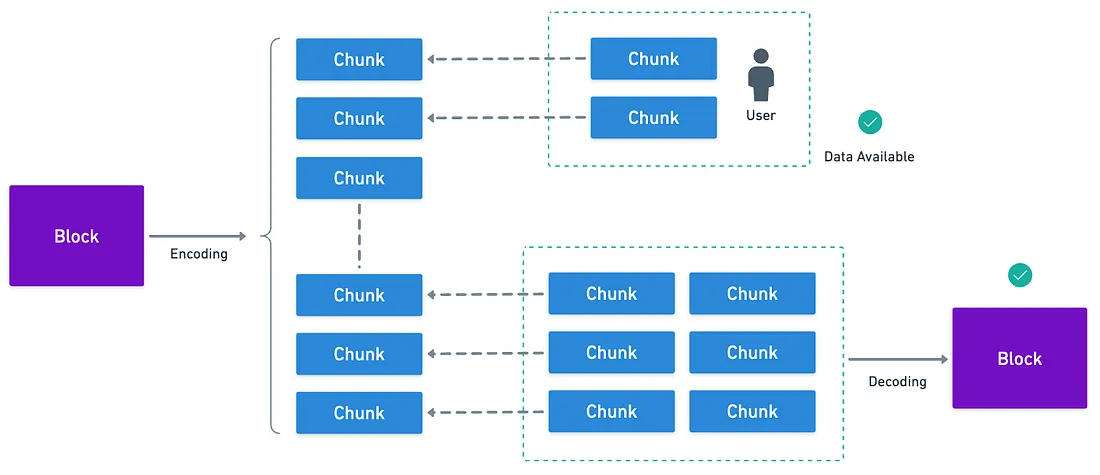
Para esto, eligieron una técnica llamada codificación Reed-Solomon 2D.
¡Es una modificación de un método que ya exploramos en la serie Cryptography 101, así que puedes leer eso como referencia! Y para la experiencia completa del agujero del conejo, aquí está el artículo real.
Para darte una idea aproximada de cómo funciona esto, Celestia toma todos los datos de transacción en un bloque, y los organiza en una matriz cuadrada — digamos que es de tamaño . Luego, aplican la técnica de codificación (Reed-Solomon) para expandir esto en una matriz , agregando redundancia tanto horizontal como verticalmente.
Luego, hacen algo realmente inteligente: en lugar de calcular una sola raíz de Merkle para las transacciones del bloque, se calcula una raíz de Merkle para cada fila y cada columna de esta matriz . Y con eso, crean una raíz de Merkle maestra que combina todas estas raíces individuales.
¿Para qué, preguntas? Bueno, digamos que quieres verificar que los datos de algún bloque están disponibles, sin consultar el bloque completo. Puedes elegir aleatoriamente posiciones en esta matriz expandida, (digamos y ). Solicitas estos fragmentos de la codificación, y también pides pruebas de Merkle válidas para esas posiciones.
Por supuesto, recibirás una prueba para la fila y columna de cada uno de tus puntos elegidos, y luego una prueba para el bloque expandido completo.
Dado que construir cualquiera de estas pruebas es extremadamente difícil sin conocimiento de los datos originales, entonces podemos decir con muy alta probabilidad que los datos son conocidos y están disponibles por quienquiera que cree estas pruebas.
¡Solo muestreando unos pocos puntos!

Es difícil encontrar una buena analogía, pero es un poco como pedirle a alguien que pruebe que tiene un rompecabezas de piezas completado sin mostrarte todo.
Pides aleatoriamente ver algunas piezas específicas — quizás la pieza que debería estar en la posición y otra en . Si pueden mostrarte esas piezas exactas, y de alguna manera probar que encajan perfectamente con las piezas circundantes a su alrededor, puedes estar confiado de que realmente tienen el rompecabezas completo.
Contenido de los Bloques
Por último, querremos ver qué vive realmente en un bloque de Celestia.
Como sabemos, el objetivo aquí no es ejecutar lógica de Contratos Inteligentes. Esto significa que las transacciones no describen funciones complejas de transición de estado.
Pero entonces... ¿Qué almacenamos? O para decirlo de otra manera, ¿cómo se ven las transacciones en Celestia?
Bueno, es una Capa de Disponibilidad de Datos de la que estamos hablando. Así que lo que queremos hacer disponible en los bloques es datos. Fragmentos arbitrarios de datos enviados por aplicaciones consumidoras, llamados blobs.
Cuando, digamos, un rollup quiere usar Celestia, empaqueta sus datos de transacción en estos blobs y los envía con una transacción PayForBlobs. Los blobs también se organizan en espacios de nombres, donde obtienen un identificador para que diferentes rollups puedan encontrar sus propios datos, e ignorar todo lo demás.
En resumen, un bloque de Celestia contendrá:
- Transacciones — principalmente transacciones
PayForBlobs, aunque hay otros tipos de transacciones, - Datos de blob de varios rollups o aplicaciones usando Celestia,
- Algún otro metadato.
Nota que las pruebas de Merkle que lo unen todo no son parte de los bloques, sin embargo, y se generan bajo demanda.
Impacto
Es un buen momento para recordarnos cómo llegamos a Celestia en primer lugar.
Toda esta complejidad técnica sirve a un propósito simple pero poderoso: hacer posible que cualquiera verifique los datos de la blockchain sin gastar un montón de dinero en hardware costoso, o consumir ancho de banda masivo.
Piensa en lo que esto significa por un momento. Recuerda que tradicionalmente, si quieres verificar verdaderamente lo que está pasando en una Blockchain (en lugar de solo confiar en alguien más), necesitas ejecutar un nodo completo. Eso significa:
- Descargar cientos de gigabytes
- Mantener conectividad constante a internet
- Tener suficiente poder de cómputo para procesar cada transacción.
El Muestreo de Disponibilidad de Datos permite que un usuario con un smartphone muestree aleatoriamente algunas piezas de datos y obtenga casi las mismas garantías de seguridad que alguien ejecutando un nodo completo.
¡Así, cualquiera puede ejecutar estos llamados nodos ligeros o clientes, y participar activamente en el proceso de verificación!
El verdadero avance es transformar la verificación de Blockchain de un privilegio costoso en algo accesible para cualquiera. Y lo importante:
![]()
![]() Mientras más personas puedan permitirse verificar, más descentralizado y confiable se vuelve el sistema.
Mientras más personas puedan permitirse verificar, más descentralizado y confiable se vuelve el sistema.![]()
![]()
Interesantemente, Celestia no es la única Blockchain haciendo esto: como ya mencionamos en artículos anteriores, Polkadot (y JAM) maneja DA a su manera y para sus propios propósitos. Ethereum también ha incorporado blobs no hace mucho (Proto-danksharding), marcando el comienzo de su hoja de ruta hacia Danksharding, que ha visto una actualización importante en el lanzamiento reciente de PeerDAS.
Resumen
Blockchain no fue concebida originalmente como el niño prodigio de las bases de datos distribuidas. Claro, resuelve cosas como inmutabilidad, resistencia a la censura y ejecución automática realmente bien, pero el almacenamiento masivo de datos distribuidos simplemente no estaba en los planes.
En un nivel superficial, esto podría no sonar tan emocionante como otras aplicaciones de Blockchain, pero es uno de los desafíos centrales en su diseño. Cada arquitectura de Blockchain eventualmente se topa con la misma pregunta: ¿cómo manejamos más datos sin hacer que el sistema sea inutilizable?
Crucialmente, no cada pieza de datos necesita el mismo tratamiento. Podríamos estar bien con almacenar cosas fuera de cadena, pero cuando se requieren garantías más fuertes, las soluciones nativas de Blockchain podrían ser mejores.
Si algo, este artículo muestra la amplitud y diversidad de desafíos a resolver en el diseño de Blockchain. Los muchos obstáculos y barreras han sido superados a lo largo de los años, pero otros nuevos han aparecido en el camino.
Sin embargo, esto solo parece alimentar aún más a la comunidad, que sigue proponiendo ideas inteligentes y nuevos paradigmas.
¡Es realmente un espacio increíble. Genuinamente lo disfruto!
Hemos cubierto bastante en la serie hasta ahora. Espero haber despertado tu curiosidad un poquito, para que puedas continuar aprendiendo por tu cuenta sobre estas tecnologías fantásticas.
Para cerrar las cosas, quiero volver a lo que sigue siendo el centro de todo en el panorama actual de Blockchain: Ethereum.
¡Te veré en la línea de meta!


¿Te resultó útil este contenido?
Apoya a Frank Mangone enviando un café. Todos los ingresos van directamente al autor.