The ZK Chronicles: Enter Hashing
It’s kind of amazing that we even got here at all using only finite fields and polynomials, isn’t it?
As far as protocols go, we even got to our first general proving system in the form of GKR. And in the theory department, we got into some pretty deep concepts, connecting different types of problems, and providing a strong theoretical foundation for many things to come.
But I mean, come on. If you’re into this stuff at all, you know there are a few elements we still haven’t touched. And of course, a prominent one we’re still missing in our quest for ZK is hashing functions.
So today, it’s finally time to incorporate them into the mix. Simple as they may seem, they will unlock some crucial superpowers for our proving systems.

Let’s start by taking a look at what exactly we’re dealing with, and then we’ll put these hash thingies to good use!
Hashing Functions
You’ve probably heard of hashing functions already. They’re everywhere: password storage, data integrity checks, digital signatures, and more. They are truly a jack of all trades.
I’m willing to bet you probably know what they are and how they work, but for the sake of completeness, let’s just go through a brief explanation.
I also have an introductory level article on this topic, which you might want to check out!
To make this introduction swift, a hashing function is just a function that takes some input, shuffles it up, and produces an output that’s entirely unrecognizable from the input.
Oh, by the way, we usually refer to the output of a hashing function as the hash of the input value!
That’s all it does, really. “To hash” literally means to chop something into smaller pieces and cook it, effectively mixing it up and creating something new out of the mixture. Like those tasty hash browns we all know and love.

In contrast to our culinary parallel however, this chopping happens in a very specific way, granting hashing functions some special properties:
- They are deterministic: every time we pass input through the hashing function, we’ll obtain exactly the same value, no matter how many times we try.
- They are diffusive: small changes in the input will produce tremendous changes in the output. This is also sometimes called an avalanche effect.
- They are unpredictable: we can’t know in advance what the output will be just by analyzing an input.
- They are irreversible: we cannot know what the input was by analyzing the output. To be a little more precise, what we’re looking at here is preimage resistance: it’s incredibly hard to find an input that produces a given output. Because of this, hashing functions are sometimes called one-way functions.
In most cases, we also care about collision resistance, which means that finding two inputs that produce the same output (or even partially-matching outputs) is very hard.
Building a function to meet these requirements is not an easy task, but it’s also not impossible.
Once we obtain such a construction though, its properties make it suitable for a plethora of applications, one of which we need to talk about right after this.
Merkle Trees
The existence of these hashing functions allows us to build complex data structures around them, of which perhaps the most well-known one is the Merkle tree.
Merkle trees come in various forms, but the simplest version is that of a graph in the form of a (yeah, you guessed it) tree. However, it’s not your “normal” graph, so to speak.
Let’s start with the most plain example possible, and that will allow us to understand how this works and why the structure is useful at a larger scale. It goes like this:
- Take any two strings. Choose whatever you like — from simple words like “hello” and “world”, to the two first paragraphs of Lorem Ipsum.
- Hash them both. We can use a common hashing function for this, like SHA256.
- Now, take the two results, and concatenate them. As in, simple string concatenation.
- Finally, hash them again.
What you’ve just done looks like this:
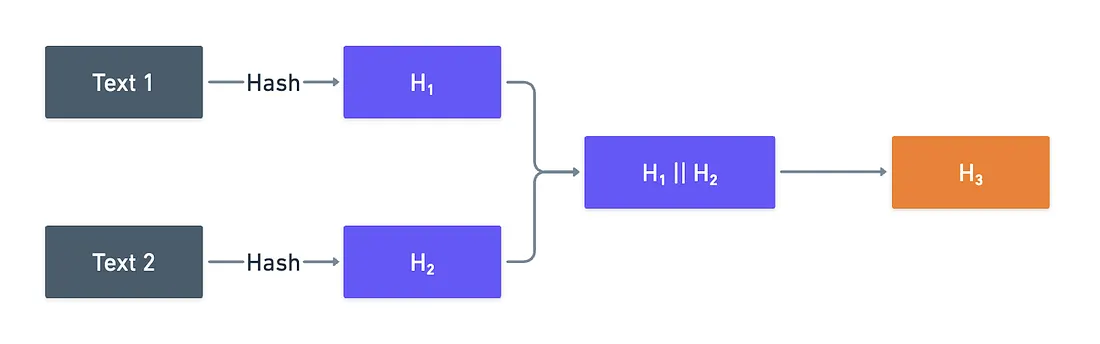
Why do all this, you may be asking? Three reasons, actually.
The first one has to do with how the information is tied together: because of the properties of hashes, a single little change in either of the original texts will result in a totally different output value (which we call the root of the tree). Also, if the hash is collision-resistant, it means it’s really hard to find other texts that would produce the same root.
All this to say: the root is a guarantee of the integrity of the original data. Any minuscule change, and the root will change dramatically. So this works as a way to commit to those initial values.
Secondly, let’s see what happens when we scale this process up. Nobody said we should limit ourselves to two inputs! In fact, we could do this same process with 4, 16, 64, or even thousands of original values, all being reduced to a single root. Thus, the second reason we do this is compression: we can commit to a huge set of data, whose integrity can be checked against a single little value.
“But Frank” — you may ask, “hashes are already compressing! Why not just hash all the inputs together in a single go?”. And you’d be spot on. Indeed, a hashing function takes an input in some potentially unrestricted domain , and maps it to a string of bits of a fixed length:
Then... Why not just hash all, and be done with this?
That brings us to our third and final reason: the ability to generate proofs of inclusion. Merkle trees allow us to prove a single input leaf is part of the tree, therefore being tied to the root, by providing intermediate hashes along the path to the root, which are called Merkle paths, or authentication paths. Like this:
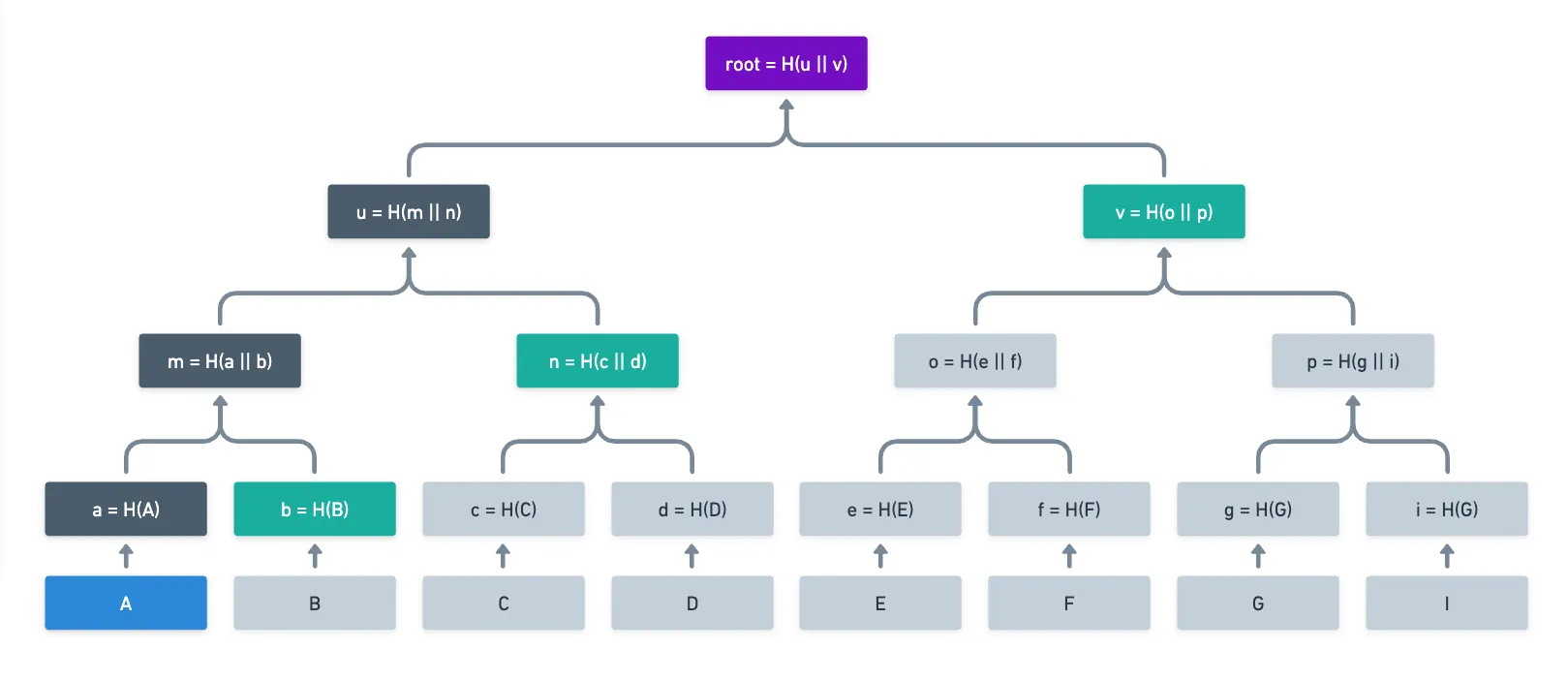
Instead of having to provide all the original data to recalculate the root, someone wanting to prove was part of the original set only needs to send the values of the green nodes, and someone verifying this can easily find the root themselves.
That’s a nice and useful trick!
Especially in the right context: for example, some blockchains like Bitcoin use Merkle trees to compress the transactions in a block, effectively providing a quick way to validate the inclusion of a transaction in said block.
But we’re here for verifiable computing and ZK. The question then is clear: are Merkle trees any good in this context?
The answer, as you might expect, is yes. However, we’re still too early to bring out the full potential of these structures. For now, I can only show you the tip of the iceberg... But I’m pretty sure that will be plenty for now!
Polynomial Commitments
A few articles back, when we first introduced the sum-check protocol, I mentioned the idea of making an oracle query to some polynomial .
Back then, we were lacking a few key mathematical concepts to really present how this can be achieved. To be fair, we still do — but hashes start unlocking some possibilities.
Let’s analyze what having oracle access might look like. Suppose you have some polynomial defined over some finite field , and you want to evaluate it at some input . There are two options here:
- You have a way to evaluate * yourself, trusting no other party.
- You ask someone else to calculate , and they provide a proof of correctness.
The first one, if possible, is the simplest solution. However, the original polynomial is often not available to the verifier, or at the very least, it would be impractical for them to calculate on their own.
Instead, the verifier could ask the prover for the value . Of course, the prover could lie — how can the verifier trust this value then?
Well, one solution to this problem (although a little crazy) involves using Merkle trees.

The idea is quite raw, but powerful: the prover evaluates every possible input for , and condenses all the possible results into a single Merkle root.
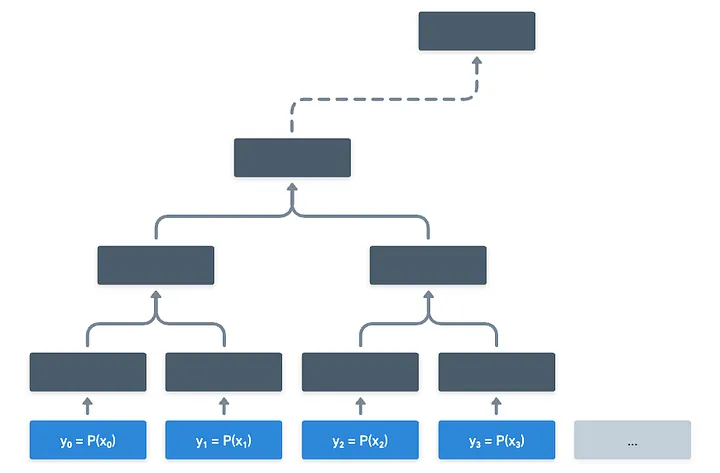
Naturally, this tree can grow large. Like really, really large. Still, the prover would need to do this one time, and send the root to the verifier, and that’s all the setup we need. In doing so, the prover has committed to the values in the Merkle tree, and can only respond with valid values when prompted.
Thus, the interesting part happens when the verifier asks for an evaluation at some value .
It’s important that the input values have some sort of ordering that matches the order of the Merkle tree leaves. The order can be as simple as , , and so on.
All the prover does is provide the value of , along with the authentication path leading to the root the verifier already possesses!
This is quite nice, because the provided proof can be checked in logarithmic time. If there are a total of possible evaluations to ask, then verification happens in steps!
Effectively, the verifier is asking for some value , and the prover is responding with the correct value, and proof of its correctness (via inclusion in the Merkle tree).
It looks expensive for the prover, yeah, but plausible. Only that... There is a huge problem with this solution: how do we know the evaluations in the Merkle tree correspond to in the first place?
That’s well beyond the scope for today’s article. But I didn’t outright lie to you guys: Merkle trees are useful for this. Let’s just say there are extra conditions we can check, given the appropriate context.
Still, we’ve demonstrated that Merkle trees can be used as the foundation for what we call polynomial commitments: ways to commit to a polynomial, so that evaluations can be checked for their validity against the commitment when asked.
There are other ways to do this, and we’ll explore more of them further down the road!
Enough Merkle trees for now though! Hashes can be used in other ways in verifiable computing, two of which are even more valuable than Merkle trees for us. Those, we’ll examine next.
Hashes in Circuits
In the previous article, we commented how we can turn any computation into a circuit satisfiability (CSAT) problem.
And what are hashing functions, if not computations? That means we can convert them into circuits!
Should we, though?
If there’s one thing we’ve learned so far, is that the cost of our proving protocols heavily depends on circuit size. Both our #SAT system and the GKR protocol became more expensive as circuit size increased, so it’s reasonable to say that we’d like to keep circuits as small as possible.
What I’m trying to get to is this: suppose we write some program that uses a hashing function, and we convert said program (we know this is possible thanks to Cook-Levin) to a circuit. How big will that circuit be?

We can measure the expected size of the produced circuits by the number of mathematical constraints hashing functions have.
Think of these constraints as the number of steps taken to calculate the final hash. We’ll be more precise in what these constraints really are later on. For now, we can envision each one of these steps as an expression that needs to be valid for the whole process to be correct — much like was the case when we analyzed circuits in the GKR protocol. And each constraint can be represented with a small number of addition and multiplication gates.
Traditional hashing functions, like SHA-256, were designed specifically for CPUs, which use boolean circuits. They make use of bitwise operations like , , or rotations, organized in mixing rounds. And to add insult to injury, they perform many of these mixing rounds (64, in the case of SHA-256). The result of this is an exorbitant number of constraints, easily reaching into the tens of thousands.
I think it’s pretty obvious this renders common hashing functions quite impractical for verifiable computing and ZK in general, because they make our proving efforts very expensive.
The next question follows naturally then: are there safe hashing functions (with all the good properties we described before) we can implement with small circuits?
ZK-Friendly Hashing Functions
Of course!
With the advent of verifiable computing, and recognizing the need for hashing functions that produced small circuits, some new alternatives were developed. Hashing functions like MiMC or Poseidon produce much smaller circuits compared to more “traditional” hashing functions, making them suitable for statement representation.
So, how do they work? There are some interesting tricks behind these constructions (like how they implement the S-box operation), but in a nutshell, the magic resides in that they use operations native to arithmetic circuits: finite field addition and multiplication.
Also, check this Rareskills article for some extra details!
This results in very lean circuits, with only a couple hundred of constraints.
Because they are designed for arithmetic circuits rather than CPUs, these functions are much slower than other common hashing functions like SHA-256 or Keccak-256. However, they make perfect sense for verifiable computing, where as we already know, circuit size is king.
For most ZK applications, Poseidon seems to be the de-facto hashing function of choice.
I imagine this is a lot of information already.
Take a pause if needed!
However, I’ve saved arguably the most important application for hashes for last. Truth is, we pretty much can’t properly continue our journey without understanding the next concept. So I’m still not letting you guys off. Sorry for that!
The Interactivity Problem
One of the big “problems” you may have identified with our proving systems so far is interactivity.
In our designs, a prover and a verifier have to interact with each other, sending messages and challenges back and forth, ultimately allowing the prover to convince the verifier of the validity of some computation.
It’s not really that this interactivity is a problem — after all, it’s what allows the systems to work in the first place. But we can at least recognize that interactivity has two complications:
- It makes the overall process slow. On each verifier challenge, the prover has to do some relatively expensive computation, which becomes the bottleneck for the entire protocol.
- It requires both parties to be active during the entire interaction. If one party disconnects or is unavailable, then the process cannot continue!
Ok, yeah... But what can we do about it? Is there any way we could do this in a non-interactive manner?
Luckily, thanks to hashes, and to the ideas of Amos Fiat and Adi Shamir, we can!
The Fiat-Shamir Transform
Let’s pause for a moment, and think why interactivity even matters.
For simplicity, let’s focus on the sum-check protocol. As a short reminder, on the first round, the prover sends the claimed sum over a boolean hypercube, and a polynomial so that:
After checking this, the verifier chooses some random value that the prover cannot predict, and this number prompts them to calculate some unexpected value , for which they need to execute another round of sum-check.
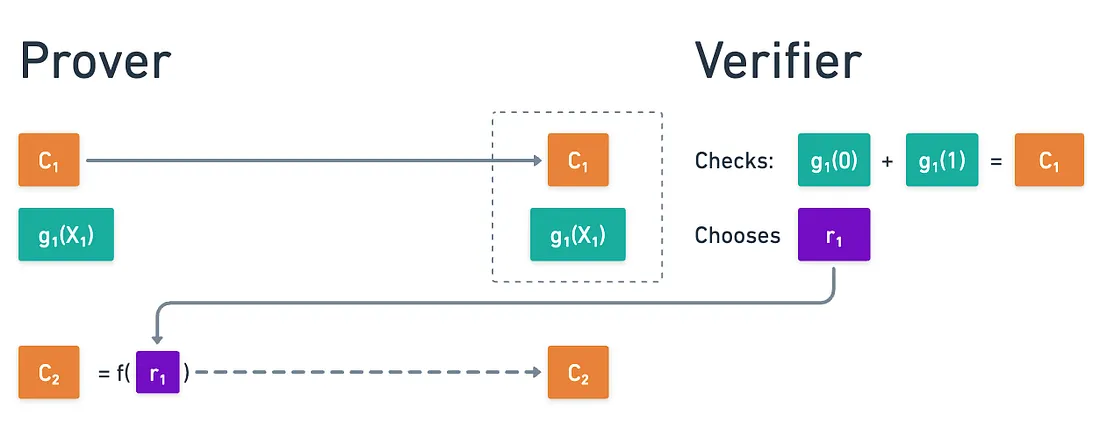
The key insight here is that the prover cannot pre-calculate C₂, because they cannot predict the choice of r₁. It is this unpredictability that makes the protocol sound, as we already saw.
And you know what else is unpredictable? Freakin’ hashing functions!
That’s the brilliant idea from Fiat and Shamir: that we can emulate the verifier choice by taking the hash of the exchanged messages:
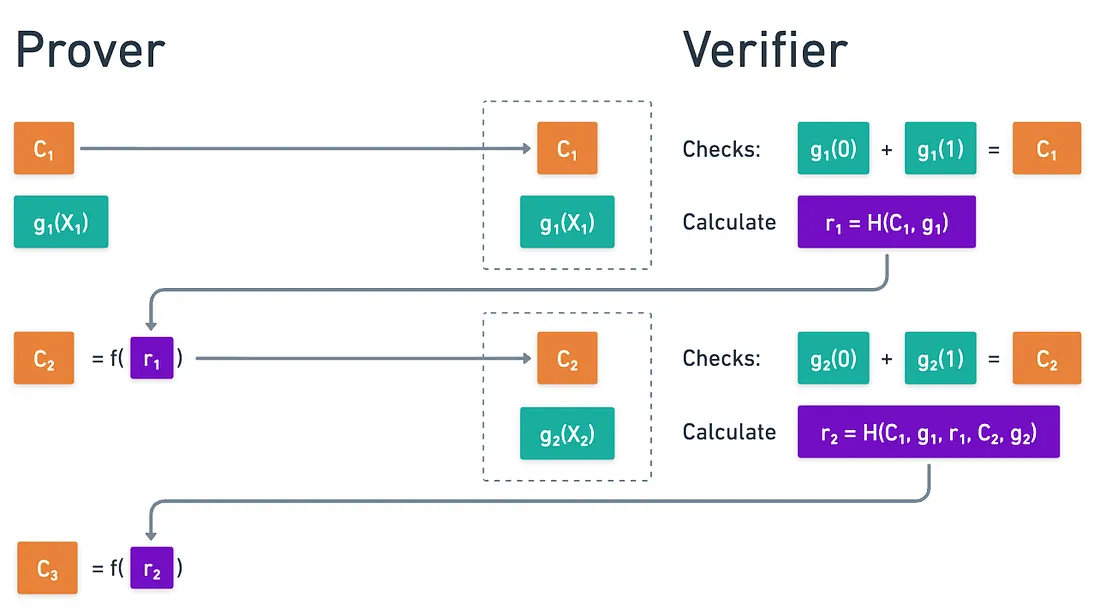
Cool! We use the pseudorandomness and unpredictability of hashing functions to entirely remove interactions! And all a verifier would need to check is that all the checks pass, and all the hashes are correctly calculated.
This is known as the Fiat-Shamir transform or heuristic, and it can be used to transform any interactive protocol into a non-interactive one, effectively removing verification bottlenecks.
Security
Of course, removing the verifier out of the equation for the selection of challenges means that the prover could potentially manipulate things.
So, is this actually secure?
The key lies in hashing the entire transcript: all previously exchanged messages, including the prover’s own responses. This creates a binding chain:
And so on.
This works because in order for a malicious prover to manipulate some challenge to a favorable value, they’d need to find inputs that hash to their desired (which is hard if we use a collision-resistant hashing function).
But changing earlier messages affects all subsequent challenges! So they’d need to find a complete transcript where all challenges work in their favor. This requires finding not one, but multiple hash collisions or preimages, and this is extremely hard. So much so, that it’s infeasible for the prover to cheat with this strategy!
Lastly, including the initial input (in our previous case, ), we make it so that not even the result of the computation can be changed. This is super important, because we bind the transcript to what’s being proven.
Strictly speaking, we’d have to get much more technical to formally prove the security of the transform. It’s too soon for that though. We’ll get there later in the journey!
The Fiat-Shamir transform is one of the most elegant and powerful ideas in cryptography. One of the most appealing things about it is its universality: it can be applied to any interactive protocol, not just the sum-check, as long as there’s a transcript we can hash.
The practical impact is enormous: proofs become portable artifacts that can be stored, and verified by anyone, anytime, anywhere.
This is why essentially every modern ZK system uses Fiat-Shamir, and is one of the crucial factors that make verifiable computing and ZK practical at all!
Summary
So there you have it! Hashes!
These little guys unlock crucial capabilities for our proving systems. They are everywhere, and provide valuable constructions that make our cryptography just work.
All the applications we saw today are very broadly used in practice. I reckon the article might be a little longer than anticipated, but believe me: every piece matters for what’s coming next. Nothing will be wasted!
Of special importance to us is the Fiat-Shamir transform. It’s safe to assume that we’ll apply it to almost any interactive protocol we design hereon, even if I don’t explicitly mention it. So just keep that in the back of your minds!
We still have quite a few protocols to cover in the series. But before we do that, we’re gonna need to start working on another crucial mathematical concept that will accompany us the rest of the journey: groups.
That will be our next destination then!


Did you find this content useful?
Support Frank Mangone by sending a coffee. All proceeds go directly to the author.