The ZK Chronicles: Commitment Schemes (Part 1)
After going through the last couple of articles, we should now be equipped with many of the core gears that make verifiable computing tick.
As we start combining these elements, rich behaviors begin to emerge: behaviors that will become the very layers that make up the modern algorithms we’ve alluded to all this time.
Today, we’ll explore one such family of constructions. It’s one of the simplest ideas in cryptography, and yet it has a crucial role in a myriad of protocols, even outside the scope of verifiable computing.
I hope that’s enough to hook you in for what’s coming! If that’s the case, let’s dig in.
Commitments
The central topic for today is cryptographic commitments.
Not that it was spoiled in the title!
The very first thing we want to understand is just what a commitment is. Informally, to commit to means to make a pledge (or we could even say a special type of promise), binding whoever places that pledge to a certain course of action.
If that didn’t sound very intuitive, don’t worry. There’s a very nice analogy to best visualize how this plays out in practice.
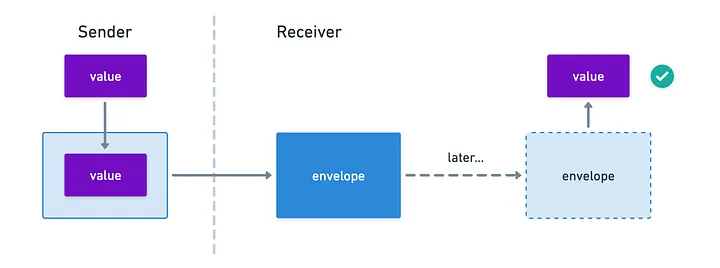
Imagine for a second you’re watching a magic show. At some point, the magician writes a prediction for some future outcome on a piece of paper, places it in a sealed envelope, and leaves said envelope on a table while the show continues.
We, as audience, cannot know what’s inside that envelope. And as the show continues, someone randomly selects a card from a deck, and immediately after the magician opens the envelope to reveal the prediction — and boom! It matches.

The reason we are impressed is because the prediction was made before the selection, and the magician made a commitment to his decision by placing it on the envelope, which conveys a very simple yet very powerful message: once in the envelope, the magician can no longer change his prediction.
What’s funny is that, after dabbling in magic for quite a few years now, I know the trick usually lies elsewhere... But let’s not spoil the fun for the believers out there!
Furthermore, the prediction is hidden from us until the big reveal.
Both of these characteristics — the message being hidden, and the prediction being made before the selection —, are crucial for the success of the trick. I think you’d agree with me that it wouldn’t be the same without the dramatic flair!
And that’s the core idea: you commit to some hidden value, and then you “open the envelope” to reveal it!
Cryptographic Commitments
It’s a good analogy, but let’s state the obvious: none of the mathematical instruments we have at our disposal work like an envelope.
So... How about we just build one?
Let’s see. We know the mechanism we’re trying to create needs to have two properties we already talked about in the above example:
- It must be hiding: we should not be able to learn what the committed value is by looking at the commitment (just like we can’t see inside the envelope).
- It must be binding: the commitment has a single valid associated value (just like we get a single value when we open the envelope).
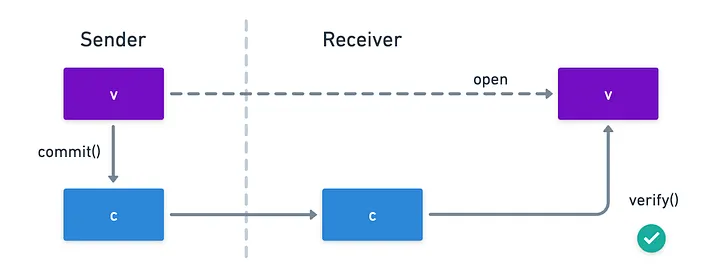
How do we do that? Imagine this: we build some function commit() that takes the original value, which we’ll call v, and produces another value we shall call , the commitment to .
Now, instead of literally opening the commitments, we want to check whether a provided value matches the commitment. For that, we build another function verify() which takes both and , and outputs either or , with the result meaning whether the provided value matches the commitment or not.
There are multiple ways to do this, each with their own interesting quirks. But there’s one strategy that’s beautifully simple, and at the same time, reveals another important aspect we must take into account.
A Basic Approach
The simplest thing we can do which works as a commitment scheme is to use hash functions! Naively, we can commit to a value by just hashing it:
Think about it:
- At first glance, the hiding requirement is fulfilled. Generally speaking, we know that recovering by analyzing is infeasible for secure hash functions.
- If a hash function is collision-resistant, you’re guaranteed that finding another value different from (say, ) that shares the same hash is also very hard. Thus, finding two valid openings will not happen, and the mechanism is binding.
Plus, opening the commitment is super easy: you just hash , and compare to .
That could be the end of the story. But... There’s a big problem.

Let’s walk through an example. Imagine we’re playing rock-paper-scissors in turns.
Yeah, weird game, right? Especially because whoever plays first is guaranteed to lose. Unless, of course, we place a commitment to our play instead of the actual play!
It would go like this:
- Alice plays scissors, but sends Bob a commitment to the play, so .
- Then Bob plays paper by sending the value to Alice.
- Finally, Alice reveals her original play, and Bob can verify the integrity of that claim thanks to the original commitment.
So far, so good. Now, what happens if they play a second round? If Alice plays scissors again, because hashes are deterministic, Bob would receive the exact same value once again! Thus, he can deduce Alice’s decision, play rock, and win.
What went wrong? Simple: the commitment was no longer hiding. And this leads us to a very important conclusion:
![]()
![]() Successive commitments to the same value must be different
Successive commitments to the same value must be different![]()
![]()
This is easily done by selecting a random value for each time we commit to a value, and throwing it into the mix:
Just to clarify, the first expression above means to randomly sample bits. And the hash is traditionally calculated by concatenating the values of and .
The new element, called the randomness (or the nonce), has the responsibility of blinding the commitments, so that no two commitments to the same value look the same. Of course, this requires providing alongside at the time of opening, but that’s a minor price to pay for the mechanism to make sense.
And now Alice can play scissors again in peace.

With this little tweak, we now have a usable commitment scheme. Despite its simplicity, it’s perfectly appropriate for the right application.
Limitations
Verifiable computing, however, demands a bit more structure. You see, the hash-based scheme we described results in a commitment value that’s just a string of bits. Other than opening it, there isn’t much else we can do. And for us, that’s a limitation.
In many cryptographic protocols, especially the ones we’re studying, we’ll need to prove statements about the relationships between committed values, all the while without revealing the values themselves.
I’ll ask you to trust me for a moment that this is a nice property to have, and we’ll see why in just a minute!
What we need then is to find a way to engineer commitments that behave like algebraic objects: elements that we can operate with (add, multiply), while preserving the relationships between the original values. Loosely speaking:
Just a small subtlety here: the operations are usually not the same. The relation should actually be a homomorphism.
No need to worry about this for now, but I want to be precise about the facts for the purists out there!
And so, the path ahead is clear: how can we build that type of commitment scheme?
Pedersen Commitments
To find some answers, we need to look no further than the other basic tools we have at our disposal.
Hashes were good at hiding the original value because of how hard it is to reverse them. In that department, we also know of another hard problem to crack: the discrete logarithm problem of groups we talked about in the previous article!
Alright, let’s try that. Say we’re working with some group , and that we can find two different generators and .
If we want to commit to some value , we first sample some randomness :
And then, we calculate the commitment like this:
This is known as a Pedersen commitment, and it’s one of the most important commitment schemes out there, both for verifiable computing and for cryptography in general.
One of the main reasons for its popularity is due to its homomorphic properties: it behaves like an algebraic object, just like we wanted. You can test this by grabbing two different commitments and , and multiplying them together:
And just like magic, we obtain a valid commitment for the sum of the original values, by operating on the space of commitments!

Before I forget, I need to address why exactly we need two generators. After all, the property we just showed would still work with a single one!There’s a tiny problem with that idea though: the method is no longer binding. Imagine our commitment was calculated as . The binding property requires that only the values are valid openings. But any pair of values of the form would be a valid opening, because the would cancel out!
By adding another generator into the equation, we avoid this troublesome pitfall.
Awesome! Pedersen commitments, done.
What remains is to see how this homomorphic property is useful in practice. Time to jump onto some action!
Circuit Commitments
In verifiable computing, we rarely care about one lonely number. What we really care about are entire computations: circuits full of interconnected values that must satisfy specific relationships.
Let’s begin small. Imagine we have a single addition gate, with its two inputs, and its result. Let’s call them , , and .
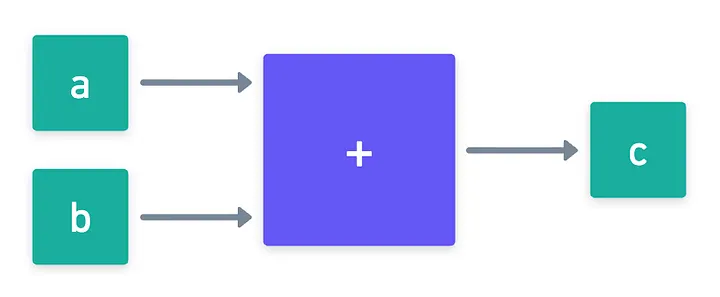
As we saw in a previous encounter, proving that this gate is correctly evaluated means to prove that . Now, suppose that in the proving systems we’ll design, we may want to commit to these values rather than revealing them from the get-go.
The naive approach here is to commit to all three values, and then send openings to all three values as well. If we were using hash commitments, this would mean we need to send over three messages at the time of opening (or 6, if we count the randomness), and that the verifier would only be able to check the relation at that time.
This is not a problem for a single gate, but scales poorly for large circuits.
With Pedersen commitments however, it’s a different story. First, we can save some communication overhead: we need only send the openings to and , and the prover can calculate on their own to compare against the original commitment:
But there’s something even more powerful happening here: the verifier can check that the relation holds without ever seeing the committed values!
We’re effectively shifting some of the workload to commit time instead of verification time!
Ok, that’s nice! For a circuit containing only addition gates, we could apply this idea to all gates, and build a nice protocol that abuses this idea, dramatically reducing communication costs, and allowing the verifier to check for consistency of the commitments on their own.
What about multiplication gates though?
Sadly, we hit a brick wall here.
For addition gates, everything worked out beautifully because Pedersen commitments are additively homomorphic. But since they are based on groups, these commitments can only support homomorphisms for one operation. Consequently, there’s no equally simple manipulation we can perform here: we cannot easily derive a commitment to from the commitments to and .
So... Are we stuck?

Not at all!
What this limitation is really telling us is that commitments alone may not be enough. To handle multiplication gates, we need a different approach: a way for a prover to convince a verifier that a relationship like holds between committed values, all without revealing them.
In other words, we need proofs about commitments!
Coincidentally, this is precisely the type of protocols we’re building in our quest for zero knowledge. We’ll use commitments such as Pedersen as sort of the algebraic backbone of our systems, while adding interactive proofs on top of that (which can be made into non-interactive proofs through Fiat-Shamir) to prove the relationships between the committed values.
In short:
![]()
![]() Commitments are not proving systems, but provide the necessary structure for proving systems to work
Commitments are not proving systems, but provide the necessary structure for proving systems to work![]()
![]()
And this should be enough motivation to keep us going!
Vector Commitments
Before we get to these proving systems though, there’s another practical question we need to address.
So far, we’ve only talked about committing to a single value at a time. This is hardly realistic: computations usually involve hundreds, thousands, or even millions of values.
That poses a real problem moving forward: sending one independent commitment per value is a textbook recipe for poor scalability.
It’s only natural to ask ourselves if we can do any better. And luckily, the answer is yes: this is exactly the role of vector commitments.
The idea behind vector commitments is straightforward: to produce a single, compact commitment that somehow manages to represent an entire list of values.
Later on, we should be able to open just a single component of the vector without having to reveal everything else. In other words, we want selective openings: proofs that a specific entry was part of the original list of values, while keeping the rest hidden.
How can we build that, you may ask? Well, say hello to a little friend!
Pedersen as a Vector Commitment
Yup!
Pedersen commitments can actually work as vector commitments. Think about it: what if instead of using just two generators and , we grab a whole family of generators ?
We can then treat a list of values in this fashion:
I will omit the product indexes moving forward just to simplify the notation a bit!
That’s it! One single group element, representing the commitment to different values.
This construction is known as a Pedersen vector commitment, and it inherits all the nice properties we care about:
- It’s hiding, thanks to the randomness and the generator . In fact, it’s perfectly hiding: even with infinite computational power, you cannot determine the committed values from alone.
- It’s binding, thanks to the discrete logarithm assumption.
- And most importantly for us, it is homomorphic: it has all those nice additive properties we already discussed.
Plus, the commitment scheme is compressing: the size of the commitment is much smaller than the size of the committed values!
That last point is crucial. See, if we have two vectors and with commitments:
then multiplying those commitments gives:
which is precisely a valid commitment to the component-wise sum of the vectors.
Pretty neat, right?

Openings
Of course, committing to a vector is only half the story. Eventually, we need to be able to convince a verifier that a particular component was included in the commitment. The naive way to do this is by revealing all the components of a vector, and of course the randomness along with them.
Wait... But what if we only want to reveal one component, and still prove it was part of the original vector? Then, this opening strategy defeats the purpose!
This is pretty much the same problem we had with multiplication gates: our nice mathematical gadget is not a proving system in itself. So while Pedersen commitments give us a compact and algebraically-friendly way to bundle values together, they don’t yet provide efficient selective openings on their own.
More advanced techniques will be required for that.
Beyond Pedersen
Pedersen vector commitments are conceptually simple and extremely useful, especially inside proving systems where we often manipulate commitments algebraically rather than open them directly.
However, in scenarios where we truly need scalable selective openings (for example, proving membership of a single element in a huge dataset) other constructions are often a better fit.
Several families of vector commitment schemes exist, each with different trade-offs.
In fact, one family is based on a construction we have already seen: Merkle trees!
But it’s too soon for us to dive too deep into those waters. Better to avoid them for now so that concepts don’t get all mingled together.
For now, what matters is the big picture:
![]()
![]() s
Vector commitments allow us to compress large amounts of structured data into a single short commitment, while still enabling proofs about individual components
s
Vector commitments allow us to compress large amounts of structured data into a single short commitment, while still enabling proofs about individual components![]()
![]()
And this idea of compact commitments, combined with proofs about them, is one of the central pillars of modern zero-knowledge protocols.
Summary
That’s a wrap on commitments, for now!
We’ve now moved a little beyond mathematical foundations territory, and are now building true components for what’s coming next.
Yeah, complexity starts to increase, and that can feel scary at first. But as I mentioned earlier, these ideas become layers that we then stack on top of each other to build our proving systems. Under this lens, you can look at the bigger picture and still understand what’s happening. The finer details are needed depending on how far you want to go.
I mean, if you’re gonna implement this stuff, of course you need the finer detail! But if you’re just using libraries to build your proofs, maybe only the general ideas are fine.
But maybe you wouldn’t be here if that was the case!
With that in mind, we can summarize today’s article quite shortly:
![]()
![]() Cryptographic commitments are mechanisms that allow someone to lock in a value while keeping it hidden, with the ability to reveal it later
Cryptographic commitments are mechanisms that allow someone to lock in a value while keeping it hidden, with the ability to reveal it later![]()
![]()
For our verifiable computing purpose, we established that the ability to manipulate commitments will be a crucial factor in the successful design of our proving systems. But we also noted that for other types of applications, simpler mechanisms (like the hash-based commitments we discussed at the beginning of this post) can be all we need.
What remains now is to understand how we can prove things about our commitments. And that will be our next stop!


Did you find this content useful?
Support Frank Mangone by sending a coffee. All proceeds go directly to the author.