The ZK Chronicles: The Random Oracle Model
Now that we've shed some light into the true meaning of zero knowledge, we're fully poised to start looking into the techniques and protocols that have made a name for themselves in the ZK space in the past few years.
Or so it seems... until we realize we're leaving a pretty big loose end unaddressed!
As teased by the end of the previous article, all of our detailed analysis on the notions of zero knowledge and knowledge soundness assumed an interactive setting, where the verifier is a real actor, generating fresh random challenges at every step. And yet, in practice, we're almost always interested in non-interactive protocols! Which means that in most cases, interactive protocols are converted to their non-interactive counterparts using the Fiat-Shamir transform.
That should at the very least spark a couple doubts. Does anything change now that we don't have a verifier to interact with? And more importantly, do any of our previous guarantees break on this new setting?
This is the matter we'll need to address today. Once we've done that though, the road forward will be fully paved, and we can charge full steam ahead into modern ZK systems.
Off we go then!
The Risk of Non-Interactivity
To get us started, let's briefly recap how the transformation that starts this whole discussion works.
The Fiat-Shamir transform (or heuristic) is a technique that allows a prover to generate a transcript for a protocol, without ever having to interact with the verifier.
However, aside from actually verifying the proofs, the verifier itself is an integral piece to the proof generation process, because they generate random and unpredictable challenges that the prover has to respond to, and whose main purpose is to make it hard for the prover to cheat. Thus, in order to turn an interactive protocol into a non-interactive one, the prover needs to replace the random verifier challenges with something else.
How do we do that, though? I mean, sure, we could just rely on the prover choosing a random challenge, but a verifier would have no way to tell if the selection was truly random, or some fabricated number to make the transcript work!
In a way, this new setting requires verifiable randomness, so to speak. And as it just so happens, we have a cryptographic primitive that gets us pretty close to that behavior: hashing functions!
For example, in a Σ-protocol, the challenge can be replaced by a hash (the commitment to the secret value ) and the initial commitment of the randomness , so . The rest of the protocol remains unchanged!
It's a low-cost and fairly reasonable change in exchange for such a powerful effect (the ability to remove interaction). And we're getting as close as possible to a true random challenge! So that should do it, right?
Well...

Yeah... it's not that simple.
Though things look nice on the surface, we cannot just overlook the fact that the verifier is now completely removed from the proof generation equation. This is not for free, and raises an important question:
Can a prover exploit this change to produce valid proofs without actually knowing the witness?
That's something we didn't have to worry about before. The prover is not fully in control: they derive challenges by hashing their own commitments, meaning they control every input to the transcript generation process. And this... should at least be enough to make us worried.
No need to blow it out of proportions... but it's safe to say this could be a massive security risk if not carefully analyzed.
So, how do we even go about answering whether this breaks any of our previous guarantees?
Well, we're gonna need to take a step back to move forward, and focus on answering a crucial question: how do we model security in cryptographic systems?
Modeling an Attacker
Simple, actually: we literally just imagine someone trying their absolute best to break our system!
I know, shocking!
In cryptography, this hypothetical entity is what we call an adversary, and is usually denoted as .
It's important to point out that we don't expect every real-world user to behave in such an extreme way. Rather, this is just a clean way to analyze security: if even a very clever attacker, using every possible strategy available to them, still cannot break the system, then we can be very confident about its design!

The goal of the adversary is clear: they need to produce a valid proof without actually knowing the witness! If they can do that, then knowledge soundness is totally demolished. The proof system would no longer guarantee that a convincing prover must truly know the secret information behind the statement, which would certainly complicate things for us!
Therefore, we need to define then are two things. First, what kind of superpowers or abilities the adversary has access to in order to accomplish their goal, and secondly, what we count as successfully breaking the protocol.
And no, by superpowers, I don't mean shooting lasers.

No, I mean something much simpler: we're trying to define what kinds of things the adversary can do with the hashing functions they execute to generate challenges. Namely:
- Can they evaluate it on arbitrary inputs?
- Can they try many different commitments before settling on a final one?
- Can they adapt their strategy based on previous hash outputs?
These are exactly the kinds of questions we need to be asking. And to formalize this, we're gonna need a framework to work with.
The Random Oracle Model
There are many ways we could go about studying the behavior of a hash function in this adversarial context, with the obvious option being to work directly with real hash functions. You know, the usual stuff: SHA-256, Keccak, and so on.
While this feels like the natural choice, it quickly becomes extremely cumbersome. These functions are all complicated algorithms, and proving precise security guarantees about their behavior is well beyond what we can realistically do.
Plus, each hashing function would need their own, dedicated analysis!
So instead, we take a different approach: we'll be analyzing security in an idealized setting, which we call the Random Oracle Model (or ROM for short).
Despite the fancy name, the model is pretty basic. All we do is think of a hash function like a magical black box, called a random oracle, which anyone can query by providing an input, to which the oracle replies with a completely random output.
Remember, this is an idealized model! We know the output of a hash is not really random, but pseudo-random (or unpredictable) at best!
Since this is an idealization of a hash, we also require an extra condition: if the same input is queried twice, the oracle must return the same output as before.
This oracle is available to everyone in the system, including the adversary. They can query it as many times as they want, adapt their queries based on previous answers, and use those results in any strategy they devise.
In essence, this random oracle effectively replaces the verifier as the source of unpredictability. Which makes it the perfect tool to formalize our analysis of the Fiat-Shamir transform.
Random oracle, check. What next?
An Adversarial Game
We can now focus our attention back on answering our original question: can an adversary exploit the Fiat–Shamir transform to forge proofs?
Again, we'll want to devise a formal setting for this. And in cryptography, questions like this are usually framed as games.

In our case, we pit an adversary against a verifier . The adversary will try to produce a transcript that would accept, despite not knowing the witness. And the rules are:
- is given oracle access to the random oracle .
- may query on any input of its choice.
- Eventually, outputs a transcript .
- The verifier recomputes the challenge , and checks whether the verification equation holds.
If the transcript is accepted, we say that the adversary wins the game. That simple!
Having framed things in this way, our security question now becomes very precise: what is the probability that an adversary can win this game?
In a nutshell, if there exists an efficient adversary that succeeds with a non-negligible probability, then the protocol is classified as insecure, because it would mean that convincing proofs can be produced without the actual knowledge to support them.
Of course, the converse is also true: if every efficient adversary has a negligible probability of winning, then our protocol remains knowledge-sound.
Okay then! What kind of strategies could an adversary use to try and cheat?
Adversarial Strategies
In our simple Σ-protocol example (after applying Fiat-Shamir), the obvious first candidate strategy would be to work backwards from the value of the challenge.
Say we pick some values and . Using these values, we can see that solving for in the verification step of the Schnorr protocol is quite straightforward:
But there isn't much else we can do afterwards, because is also required to satisfy:
By the way, from this point forward, I'll stick to the notation that's characteristic of the Schnorr protocol, for simplicity. But please bear in mind that other protocols will have other inputs to !
Because and are picked at random, it's highly unlikely that the calculated value of will happen to produce . The best an adversary could hope for is a very lucky coincidence, which by the rules of our game, means the protocol is secure against this strategy.
That could just as well be the end of the story, but...
It feels like we're missing something, because the strategy itself (which, if you recall from the previous article, is exactly how a simulator behaves) won't work. But what happens if we raise the stakes a bit? Even though we may not know the details, we can imagine an adversary smart enough to thwart our defenses, and still produce a valid transcript!
Therefore, what we do is assume such an adversary exists. If we do that, then the problem of proving the Fiat-Shamir transform is secure reduces very nicely to a much more manageable form: all we have to do is prove that this assumption leads to a contradiction!
For this though, we must refrain from picturing this adversary as a shady guy sitting in front of multiple screens with a black hoodie on.

Rather, it's much more convenient to think of the adversary as an executable algorithm we'll denote . We may not know the internals, but we still know what the algorithm should do: pick an initial commitment , query the random oracle as many times as needed, and eventually produce a valid transcript , all the while not having access to the actual secret witness.
And this formalization is all we need to get to our contradiction.
Tricking the Adversary
Okay cool, we have the algorithm . We run it one time, and get an accepting transcript . What do we do next?
Well, we know one thing for sure: no matter what strategy the adversary uses, if they eventually manage to output a transcript that passes verification, that means the value must equal . And since the adversary does not know the output of the oracle in advance, the only way they could have obtained that value is by querying the oracle on the input at some point during their execution, right?
In other words: every successful attack must involve a query to the random oracle that outputs the challenge present in the final transcript!
It might seem rather obvious, but we can take advantage of this, and this where the ROM really shines. You see, since we know what query the adversary will be making, what if we run the algorithm a second time, but changing the response of to some different challenge ?
Again, assuming the adversary has some unknown efficient strategy at their disposal, they should be able to produce another accepting transcript , unaware of our change to the random oracle's response.
So at this point, we have two accepting transcripts for the same commitment, with different challenges. But wait, doesn't that mean...
Exactly what you were thinking! Because we're dealing with a Σ-protocol, special soundness guarantees that we can extract the witness from the transcripts and !
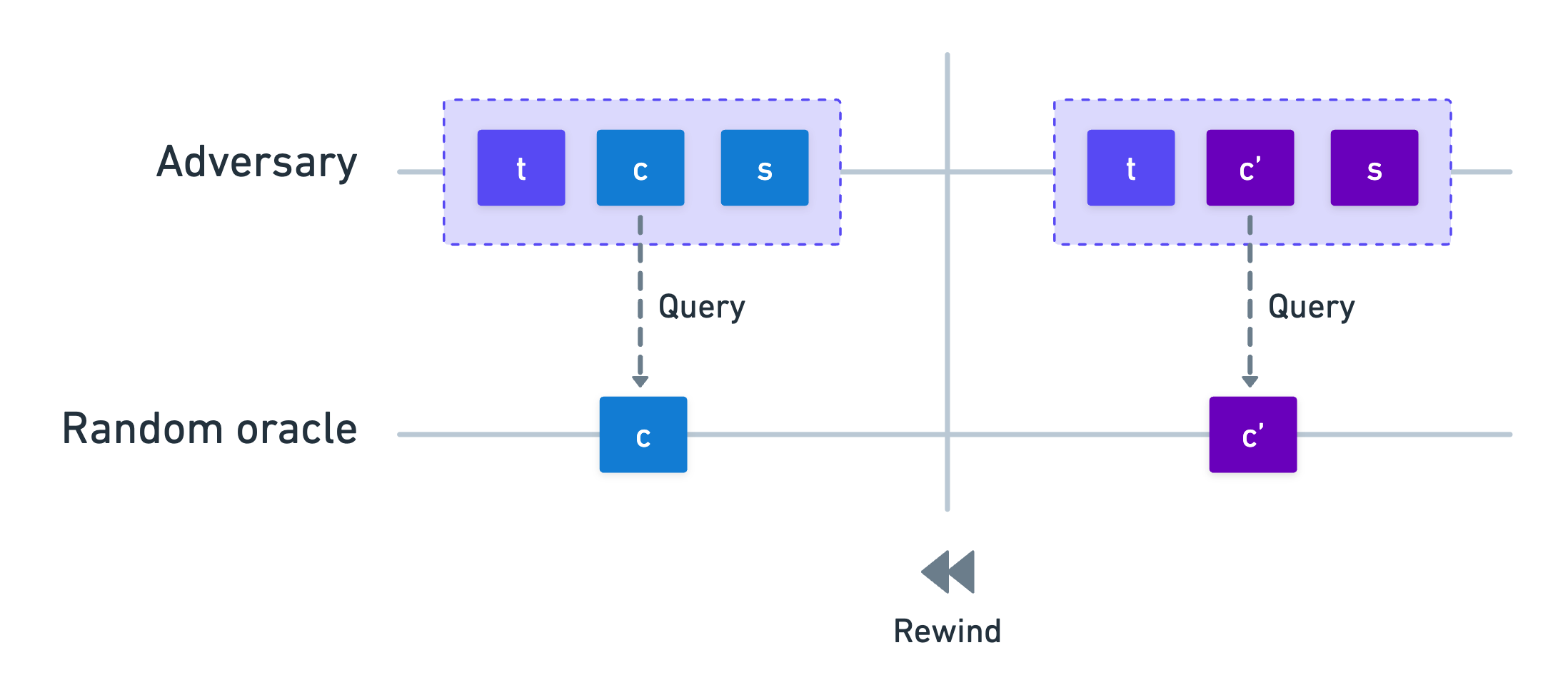
And therein lies the contradiction: an adversary capable of forging proofs in the Fiat–Shamir setting would immediately hand us the witness itself. But we assumed the adversary doesn't know the witness - so there's nothing to extract!
That's the core principle at play here: if we can replay the adversary algorithm and adjust some query results along the way, we should be able to extract information from the adversary that they don't really know, which shouldn't even be possible.
This mechanism of executing twice from the same initial state, intercepting a single oracle query and changing its response, is what's formally called rewinding. It's just a different way to think about what we're doing: we rewind execution to the point where the query to the random oracle was executed, and change the response.
And this rewinding ability is what guarantees the knowledge soundness of the Fiat–Shamir transform, under this ROM setting we're working on.
Of course, more complex protocols may need more than two executions for a successful extraction, so the formalization of this argument for arbitrary protocols requires a little more work. It's really not necessary for us to plunge into though, because the intuition is much the same, execute, rewind, and repeat until you can extract the secret.
If you're curious though, the formalization is known as the Forking Lemma.
What About Zero Knowledge?
Great! We've shown that knowledge soundness survives the Fiat-Shamir transform. But if we learned something from the previous article, it's that this is only half the story!
There's still one important concern to address: what about zero knowledge itself?
Well, recall that the whole zero knowledge analysis was built around the notion of a simulator: an algorithm able to produce valid transcripts without knowledge of the witness, that operated by picking and at random first, and then computing backwards from those values.
As we've already discussed, this trick hits a brick wall immediately in our new setting, because the verifier will recompute , and check that it matches the transcript. If the random oracle really responds as a random oracle, then it's highly unlikely for this strategy to succeed.
But we've been fiddling around with the oracle responses already! So could we not use the same trick once again?
Indeed! You see, the ROM is actually all about controlling the output of the random oracle to our convenience.
It's a model that sits in the middle between pure hash functions, and an actual verifier that can cleverly pick their challenges.
Therefore, this gives us exactly the tool we need. The simulator doesn't just query the oracle: it can control its output! So before anything runs, the simulator can simply program the oracle's response for the query on to be whatever it has already chosen!
This is sometimes called the programmability of the random oracle, and it's one of the most important features that makes the ROM such a useful model.
With that in hand, the simulation strategy is almost identical to the interactive case: choose and at random, compute , then program the oracle to return on the expected queried input (in this case, ), and output . And just like that, we get an accepting transcript, indistinguishable from a real one, with no knowledge of the witness whatsoever!
Easy!

Summary
And that finally closes the chapter on today's questions around Fiat-Shamir. Do the guarantees survive in the non-interactive setting? In the Random Oracle Model, the answer is yes!
The two arguments we saw are elegantly symmetric:
- For zero knowledge: the simulator doesn't just query the oracle, it programs it, setting the response in advance to produce a consistent fake transcript that's indistinguishable from a real one.
- For knowledge soundness: any successful forgery must involve a specific oracle query, and rewinding the adversary with a different response at that point lets us extract the witness, which is a direct contradiction.
Or in a single line:
In the ROM, the oracle's programmability preserves zero knowledge, while its observability preserves knowledge soundness
Along the way, we also picked up a few reusable tools: the ROM as an idealized framework for security analysis, the game-based formulation of attacks, and the rewinding argument that you'll see again and again in soundness proofs.
As always, there's much more to say. The ROM is an idealization, after all - and real hash functions aren't truly random oracles.
Studying Fiat-Shamir with concrete functions is an active research area, and hinges on a property called correlation intractability, which is well beyond the scope of this article!
Still, the intuition we built today should be the main takeaway: while removing the verifier also eliminates the true source of randomness, doing so can still be perfectly valid.
With these final pieces in place, the road ahead is finally paved for us to move on to the realm of modern zero-knowledge systems.
And we'll begin this last leg of the journey with something we've been postponing for quite a while now: how to turn circuits into polynomials!
Until then!


Did you find this content useful?
Support Frank Mangone by sending a coffee. All proceeds go directly to the author.