The ZK Chronicles: Math Foundations
With the introduction to the series behind us, it’s now time to start working on our toolkit, so we can set sail towards the goal of crafting these proving systems we’ve already alluded to.
I sincerely hope the previous article was not too scary. To make up for it just a tiny bit, I’ll say that the concepts we’ll be looking at today are not too complicated, while at the same time having the added benefit of being quite fundamental for any serious cryptography.
That’s a good offer if I’ve ever seen one!
However, a word of caution: as we go further into our journey together, we’ll require even more tools. Of course, we’ll talk about them in due time – but I just don’t want to send you off believing this one article is enough preparation for the rest of the road.
With that, the context is clearly set! Where do we get started then?
Finite Fields
In cryptography, precision is of prime importance.
What I mean by this is that algorithms need to be consistent. Just imagine a digital signature that works only occasionally — I think you’d agree with me that it would be a (pardon my French) shitty algorithm.
Thus, our basic units of information, or the way we represent things from this point onwards, must be such that we avoid little errors in operations that might blow up if left unchecked.
If we get really picky here, this is not absolutely true — some methods based on the learning with errors problem admit small errors, but still work just fine because they are expected and accounted for with special techniques.
Integers are pretty good at that: by avoiding floating point operations, we keep things clean and consistent. It should come as no surprise then that the most fundamental structure we’ll be building upon is a set of integers: what we call a finite field.
Strictly speaking, a field is defined as a set of elements, for which we can define four operations: addition, subtraction, multiplication, and division (except by zero or zero-like elements).
This should sound familiar — the real numbers we know and love are a field!
When I say “we can define”, I mean we have clear rules to perform the four operations, and that the result of them must also be a part of the field. That is, we imagine the set as our universe of possibilities: anything that’s not part of the set simply doesn’t exist for us. This will make more sense in just a moment.
We sometimes require the addition of an extra element (to the set). This is a useful but more advanced concept, called field extensions.
A finite field is just a field with a finite set of elements. So, something like this:
Some questions should come to mind immediately after looking at that expression. For instance, is not part of the set. What happens then?
This is exactly what I meant before: addition is not well defined, so we’d have to kinda “extend” our field to include the new element. Something similar happens with the other operations.
If we had to add a new element for every possible result, our set would just grow infinitely! So it seems we’re already getting into a mess right from the get go...
Do not fret, young one. I said these four operations have to be defined, but I never said how!

Since the standard operations don’t seem to work in this context, we’ll need to figure out other ways to define addition, subtraction, multiplication, and division. There are in fact multiple ways to do this — but there’s one in particular that seems the most naturally suited for our needs.
Modular Arithmetic
All we have to do is use the standard operations, and then pass the result through the modulo operation:
Nothing too fancy, eh?
This works because the modulo operation casts all results into our original set, even negative numbers. All we need to do is take the results modulo , the field size. In the example above, this number is of course .
A tiny problem remains though: what about division? Fractions are not allowed in our finite fields, because we have no notion of fractions in our set to begin with.
This will require a bit of a shift in perspective. You see, any division can be interpreted in an alternative way: multiplication by a reciprocal.
A quick example will help here: dividing by (so ) is exactly the same as multiplying by . In this case, is the reciprocal of — and we can write it as .
As I mentioned before, the notion of a reciprocal doesn’t make sense in our context, because fractions are not allowed.
Not all hope is lost though — there’s a particular piece of insight we can pull from reciprocals, that will give us clues on how to tackle this problem. Concretely, any number (except ) and its reciprocal satisfy this relation:
So here’s the idea: for each element in our field, is it possible to find some number that when multiplied by (modulo ), results in ?
Of course, excluding !
Interestingly, the answer depends on the value of . If such a number exists, it’s called the modular inverse of over , and the condition for its existence is that and are coprime.

Coprime numbers are just fancy naming to describe two numbers that share no factors — this is, their greatest common divisor is .
Here’s another clever piece of insight: when itself is prime, every single non-negative integer less than (except ) is coprime with it. In other words, all elements in our set will have an inverse, which in turn implies we can define division for the entire set.
And with that, all the required operations are defined, so our finite fields are ready to go!
What can we do with them?
Polynomials
Well, quite a lot actually!
For our purposes, perhaps the most important thing we can do is build polynomials over finite fields — and polynomials, as we’ll later see, are the secret sauce behind modern proving systems.
A polynomial is an expression, which has one or more variables, and can only involve a few simple operations: addition, subtraction, multiplication, and exponentiation (using non-negative integer powers). Something that might look like this:
As you can see, each term is comprised of the multiplication of variables raised to some power (which if not explicit, is just a ), and another “plain” number we call a coefficient. Again, if the coefficient is not explicit, it just means its value is .
We also need to define the degree of a polynomial: it’s the highest sum of exponents in any single term. In our example above, the term has degree (since ), and that’s the highest degree of any term, so has degree .
Earlier, I mentioned that polynomials are built with just addition, subtraction, and multiplication — so we assume that the values represented by variables admit these operations. That is, we’re assuming, for instance, that multiplying is fair game. Does this ring any bells?

Right! It sounds a lot like fields, so they seem to have something to do with all this. And sure as hell, polynomials have to be defined over some field.
What’s more, if we choose a finite field, meaning we only use field elements as coefficients, and we restrict variable values to the finite field as well, then the output of the polynomial will also belong to the field.
The set of polynomials defined over some field is usually denoted .
This is quite nice. We can use our previously-defined finite fields pretty much unchanged — so this really seems like fertile ground to build stuff upon.
Polynomials have countless applications. We’ll be using them primarily as building blocks, because of two areas they are very good at: representing computations, and encoding information.
And I know — all these definitions will feel kinda abstract in isolation. So let’s tackle this next part through a more practical lens.
Encoding Information
One of my claims just now was that polynomials were good at encoding information — but how can that be? After all, they are just expressions we can evaluate. What good is that for encoding?
Believe it or not, the secret lies in an unexpected suspect: the coefficients.
Let’s focus on univariate polynomials for a second. Listing the coefficients of the different terms (let’s say from highest degree to lowest) results in a list of field elements — in other words, a vector of integers.
Forget about polynomials for a moment: a vector of integers can represent just about any kind of information! What’s more, imagine our field is , so we just have and available. That’s exactly machine language — strings of s and s!
Okay, that’s cool... But why not use vectors directly? The only reason we’d want to interpret these vectors as polynomials is if there was something to gain from doing so. And in fact, there is.
Interpolation
I’ve talked about this in a previous post. I recommend taking a look at that for a more step-by-step guide!
Take some polynomial in in . Say we choose a few points , , and so on, until we have points (so we get to ). When we evaluate the polynomial at these points, we simply get a bunch of field elements — one for each different input.
We call the pairs evaluations or evaluation points of . Although, terminology is sometimes used quite loosely, and “evaluations” might refer to only the results.Also, notice the notation: variables are written in uppercase, while evaluations are lowercase. This will be the case for the rest of the series!
Okay, cool, evaluating seems easy, so here’s a trickier question: can we go the other way around?
This is: given a bunch of evaluations through , can you find the polynomial that generated said points?
Yes we can. The process is called interpolation (or Lagrange interpolation), and it’s extremely useful. As long as we’re mindful of a couple details.
Let’s see. A polynomial of degree one is just a line:
Flash quiz: how many points do you need to define a line?

We need at least two points. In fact, if we have more points, they need to be aligned, or else they wouldn’t define a line, but some other function.
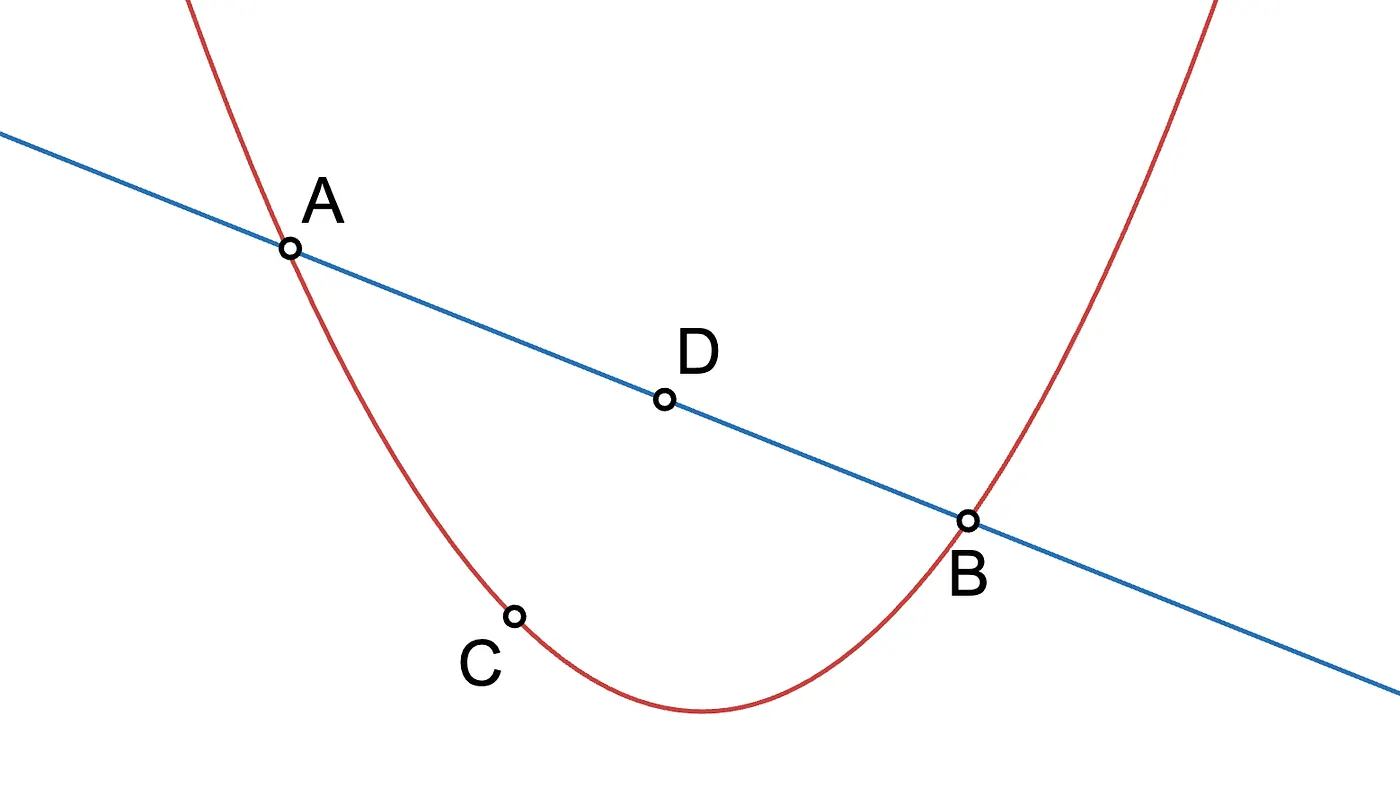
In the previous example, it is clear that interpolating three points yields a polynomial of at most degree two (a parabola), but it could also be of degree one if the points are aligned, or degree zero if they are aligned vertically.
This generalizes nicely to the following:
![]()
![]() Interpolating points yields a polynomial of degree at most
Interpolating points yields a polynomial of degree at most ![]()
![]()
Conversely, we need at least points to correctly encode a polynomial of degree . And this has the following amazing implication: if we take any univariate polynomial of degree , we can encode it by evaluating it at or more points. And then, anyone receiving those (or more) points could recalculate the original polynomial via interpolation!
So in a way, having a bunch of polynomial evaluations is an alternative way to represent some polynomial!
Now you should then be able to answer this very easily:
That’s all good and dandy — but how do we actually interpolate?
Lagrange Polynomials
Though there are faster ways to do this (via the Fast Fourier Transform), the canonical method is very clever, and it also provides some nice insights. So let’s look at that.
The idea is the following: suppose we have a set of evaluations. For a single one of those, let’s say , we can build some special polynomial that will have a value of for all values except , and exactly the value for . Let’s call that polynomial .
It’s as if we were “selecting” mathematically using .
Why would we do this? Think of it this way: if we multiply such a polynomial by , then we’ve just fabricated a small function such that:
Because is an evaluation of the original polynomial, what we want to get from the interpolation process is a polynomial such that for all our evaluations — so it seems gets us halfway there.
To get our interpolated polynomial, all we need to do is add up all values of for all our evaluations:
And voilà! That will be the result of our interpolation. Visually:
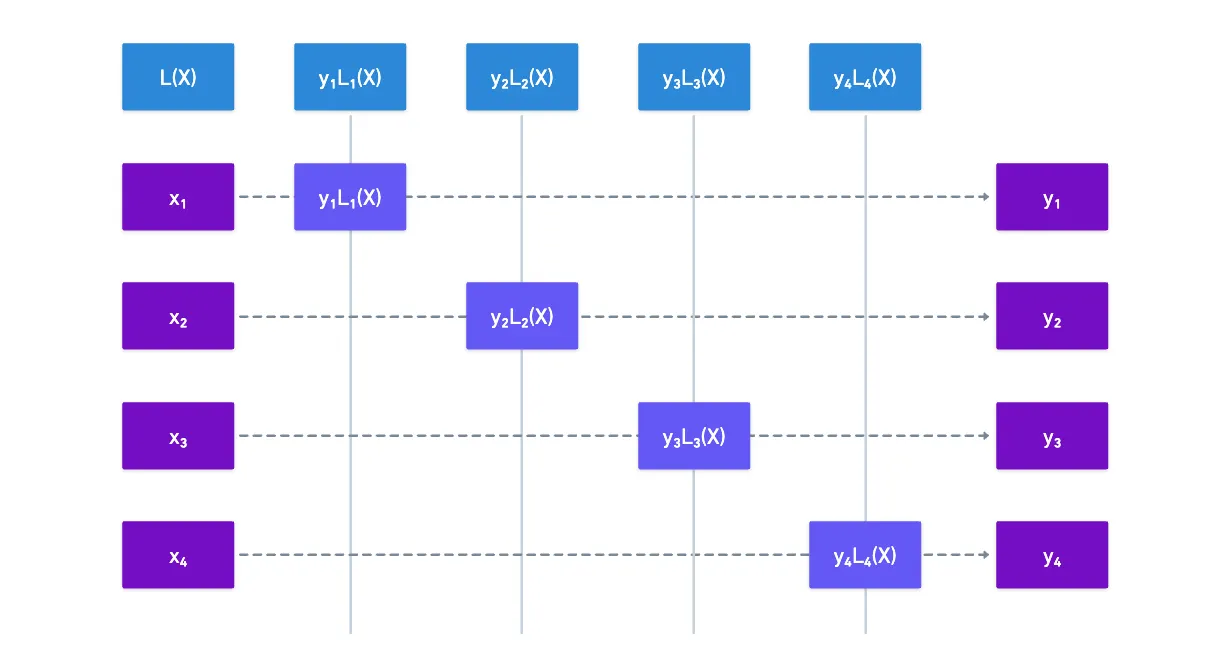
All that remains to nicely tie everything together is to determine how those are defined.
Roots
Let’s recap our requirement real quick: each needed to equal when evaluated on , and on all the other evaluations.
A polynomial evaluating to is sort of a special occurrence. So much so, that we give these values a special name: any value such is called a root of the polynomial.
Despite their apparent simplicity, roots are very powerful. The main reason for this is the existence of an important theorem, called the Fundamental Theorem of Algebra.
As a general rule of thumb, when you see something called “fundamental” anything in maths, know it must be some seriously important stuff.
Simplifying a bit, one of the most important consequences of this theorem is that any univariate polynomial can be expressed as a product of linear factors:
A very important observation follows from this expression: a polynomial of degree has at most roots. This is such an important lemma that it doesn’t hurt to repeat it, for some dramatic flair:
![]()
![]() A polynomial of degree has at most roots
A polynomial of degree has at most roots![]()
![]()
This fact is extremely important, and results in some of the most powerful tools at our disposal. We’ll put this on hold for now though, but know that we’ll come back to this very soon.
Now, circling back to interpolation, it turns out this form is quite useful. It’s clear that when we evaluate any of those values, we’ll get . We can use this to our advantage here: the polynomials need to be on all values except , which means they are roots of ! Therefore, we can construct as:
We’re intentionally omitting so that it’s not a root of the resulting polynomial.
Fantastic! The only detail we’re missing now is tuning that coefficient so that we get exactly . A simple normalization of the expression will do: take whichever value produces at , and divide the whole expression by that. This way, when evaluating , we simply get .
The full expression is then:
And that’s pretty much it!
The set of these guys is called a Lagrange basis. We might need to dig deeper into what this naming means later, but for now, the name should suffice for reference!
Summary
Alright! That’s gonna be it for today.
What we have for now may seem a little underwhelming. I mean, all we have are numbers and expressions — and these things probably feel a little basic.
Admittedly, there are a lot of layers of complexity to peel from these rather plain elements we’ve seen so far. But I don’t think it would be either practical or instructive to do so now.
Instead, it would be better to start exploring the applications that make use of these concepts. As we start using these tools, their potential will start becoming more apparent.
So on our next encounter, we’ll be looking at one of the simplest yet most fundamental protocols we can craft out of these building blocks presented today.
See you soon!


Did you find this content useful?
Support Frank Mangone by sending a coffee. All proceeds go directly to the author.