Blockchain 101: Handling Data
This is part of a larger series of articles about Blockchain. If this is the first article you come across, I strongly recommend starting from the beginning of the series.
Last time we met, we took a brief tour through the applications of ZK technology in Blockchain. If you recall, there were two main reasons why ZK is finding its way into Blockchains: fast verification, and small proofs.
Fast verification is easy to understand. The role of validators is to — you guessed it — validate blocks! So the faster they can get it done, the better it will be for the protocol overall.
That’s the theory, at least — there are some limitations to this, as we saw in the previous delivery!
But why exactly would small proofs be important? Well, there are essentially two things we should worry about. And as we’ll soon discover, these issues will catapult us right into the heart of today’s discussion: Data Availability.
So let’s start today’s discussion by touching upon this question.
Coffee ready? Let’s go!
Data in Blockchain
Let’s talk about ZK rollups for a second.
As we already know, ZK rollups post proofs of their state transitions to their respective layer 1. This is of course done so that they avoid posting their full transaction history. But why does this matter?
Anything that’s posted on the layer 1 Blockchain will need to be checked by validators. And for this, information must be gossiped around, so that every validator has all the information they need to inspect and validate.
Thus, the first problem comes in the form of efficient communication: the more information they have to share between them, the slower the overall consensus will be.
This is true for any kind of information validators need to check. And since information is contained in blocks, there’s a balance we need to be mindful of:
![]()
![]() How much information we stuff into blocks versus how slow the network will be
How much information we stuff into blocks versus how slow the network will be![]()
![]()
When designing a Blockchain, this is one of the key elements we need to worry about. To solve the problem, Blockchains in general impose limits on block size to keep their block times consistent.
It would be great if that was the end of the story. But unfortunately, this created another problem: scarcity.

Blockspace
As a Blockchain sees more and more traffic, it will have more transactions to validate through. But since blocks have a limited space, there’s only so much that can be processed at a single time.
So then, who gets their transactions included? Who will have to wait?
Well... How about we let that regulate on its own? We make transactions more expensive when there’s a lot of demand, so not everyone’s willing to pay, thus reducing the amount of transactions that need to be processed.
See what happened? We just put a price tag on Blockspace, and exposed its price to the tug of war of supply and demand. We just created a scarce resource.
In other words, publishing data into a Blockchain isn’t free, as space (more precisely, persistent distributed memory) in these environments is scarce, because it needs to be scarce for the network not to be slower than a sloth on a bad day.

In conjunction, these factors are the reason why we care about proof size: to pay less network fees.
This is the essential problem of Data Availability — a problem that, at its core, stems from the need for efficient communication between validators.
Now, given these constraints, what can we do about this?
Several different approaches are possible, depending on how deep we’re willing to go. Let’s start simple.
Off-Chain Storage
Let’s address the elephant in the room first:
![]()
![]() Do we need to put everything on the Blockchain?
Do we need to put everything on the Blockchain?![]()
![]()
Imagine you want to attach a JSON to some transaction, perhaps containing some important metadata. We know this to be suboptimal from a storage perspective: transaction costs will rise the more data we want to stick in there.
But why put that JSON on the Blockchain? The usual go-to answer is transparency: we want everyone to have access to this information so it’s easy to audit.
That’s completely fair — but really, we don’t need to store all the information on-chain for it to be auditable and transparent. All we need is a way to use the Blockchain to verify that some claimed information, stored elsewhere, is correct.
Hashes to the Rescue
Thankfully, we can resort to simple cryptographic techniques to do this.
Hashing is super useful on this account. Because of their properties, a hash of a document works both as a practically unique identifier, as well as solid proof that the original document is unchanged.
With hashing, it’s really easy to split the problem: just store the document elsewhere, calculate its hash, and publish said hash to the Blockchain.
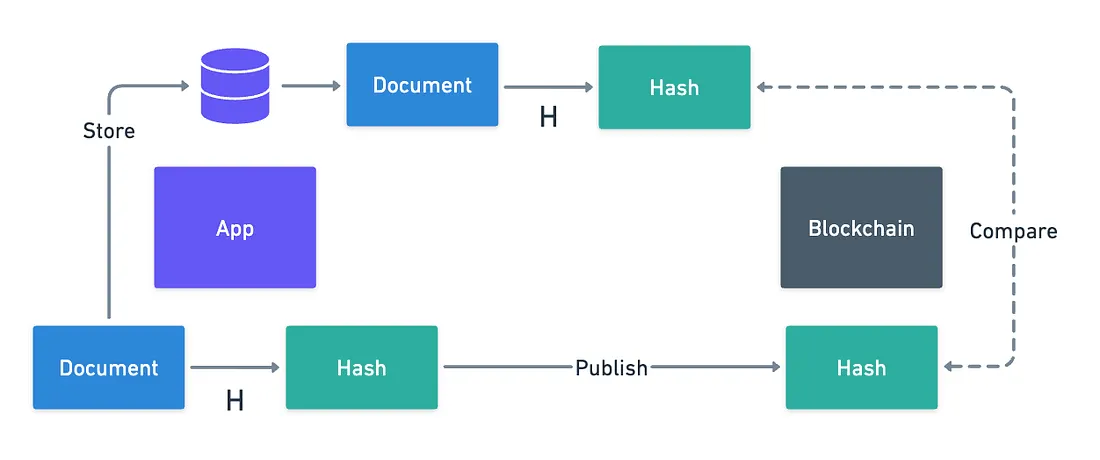
Easy, right? Except there’s a huge problem: what happens if the original data is lost?
Hashing functions are irreversible by design, meaning we should not be able to recover the original data from the hash. So if data is really lost, then there’s no way to get it back — and we’re stuck with some meaningless hash permanently stored on the Blockchain.
Yeah... Not ideal.
Since the hash isn’t going anywhere, what we can do is improve the way we store the original information. And heck, if we relied on decentralization to make Blockchains durable and immutable... Why not try something similar with off-chain storage?
IPFS
This is exactly the idea behind one of the most popular off-chain storage systems: the Interplanetary File System, or IPFS for short.

IPFS is also a distributed network of nodes, whose sole job is to store data. The content itself is content-addressed, with the hash of the content doubling up as its identifier. This ensures that any data you retrieve, irrespective of where you get it from, has not been tampered with.
You can imagine that designing such a system also comes with its own set of nuances. And you’d be right.
First, let’s try to picture where data would actually be stored. Will every node keep a full copy of every single storage item? That would seem unnecessary — we could distribute the load, and have each node store a fraction of the files. As long as one node has your file, the network will be able to recover it.
A single node storing a file is said to be pinning the file, in distributed storage systems jargon. Everything will be fine as long as at least one node is pinning your file — but if that doesn’t happen, then information will be lost all the same.
So perhaps you’ll panic a little when I say this, especially if you’ve been using IPFS for permanent storage: IPFS does not guarantee file pinning.

Yeah, what you just read. IPFS is more suited for making data temporarily available.
But don’t panic just yet!
Pinata
Pinata is essentially IPFS on steroids.

I love the logo.
Its goal is simple: to ensure a file remains available in IPFS. They provide pinning as a service, which in short means that as long as you’re paying them, they will ensure that your file is always pinned on IPFS. Effectively, we can think of Pinata as a set of IPFS nodes that guarantee our file will be pinned forever — or at least, as long as we’re paying.
As good as this sounds... There’s a catch. Can you guess what it is?

By using Pinata, you’re introducing a centralized dependency back into your system. So if Pinata goes down, or simply decides to stop pinning your files, you’re back to square one. Plus, you’re trusting them to actually keep their promise — there’s nothing stopping them from unpinning your files if they decide your content violates their terms of service.
Oh and by the way, before I forget: there’s also Arweave, which takes a different approach to permanent storage. Instead of requiring ongoing payment like Pinata, Arweave uses a one-time upfront payment model where users pay once for permanent data storage.
I don’t want to keep packing things into this article, so it’s just another thing you’ll have to check on your own!
You know, the classic trade-offs. For many applications, this is completely acceptable. But others may require stronger guarantees.
Which takes us to the next level of our exploration.
Data Availability Layers
To be fair, the solutions we’ve looked at so far are more than enough for many use cases — but we can’t just overlook the fact that they involve some sort of compromise.
But we’re thinking about solutions outside of the Blockchain itself. While we know the reasons for this, it’s undeniable that Blockchain is better suited to solve these issues we’ve encountered in these other off-chain systems — Blockchains are persistent, in contrast to IPFS, and they are also censorship-resistant and decentralized, in contrast with Pinata.
What if we could get the best of both worlds? Could we not have a Blockchain network designed for Data Availability rather than general computation?
The answer is yes. And it’s exactly what Data Availability Layers try to solve.
Celestia
One such example of a Blockchain that puts Data Availability at the center of its design is Celestia.

As we’ve mentioned before, most Blockchains have been built with this one-stop-solution mindset — but there’s value in specialization.
To put this into perspective, we have already seen a case where Smart Contract functionality was stripped away from a Blockchain: Polkadot. The idea is that by focusing or specializing on something, we can try to do it better than if we tried to do everything at once!
Celestia is not designed to be a general-purpose Blockchain. It was conceived to do one thing very well: making data available. This way, other Blockchains can build on top of this native data availability, while figuring out how to handle logic on their end.
What makes Celestia particularly appealing from a technical standpoint is that they have a great solution to a problem that many Blockchains have had a hard time dealing with.
Data Availability Sampling
Whenever a validator checks a block, it’s clear they need access to the entirety of its contents. We don’t want to leave anything to chance: everything needs to be thoroughly reviewed. So they need to download entire blocks.
But here’s a question: does everyone reading the Blockchain need all this information? Do we care about all the contents of blocks, or do we mostly care about the resulting state?
Think about this: most users don’t really care about most transactions in a block. And as blocks get bigger, it becomes impractical for said users to verify the chain, as in verifying every block.
Sure, they can do it, but they consume bandwidth, memory, and resources, while not really needing to verify everything.
It would be much better to simply ensure that verified blocks exist, and that their information is available and accessible in case you really need it, right?
Celestia solves this with what’s called Data Availability Sampling (or DAS for short).
Basically, what they propose is to encode blocks in such a way that individual users can simply download a small portion of a block’s information, and guarantee that the rest of the information will be there if queried.
And with enough chunks, you can recover the full block.
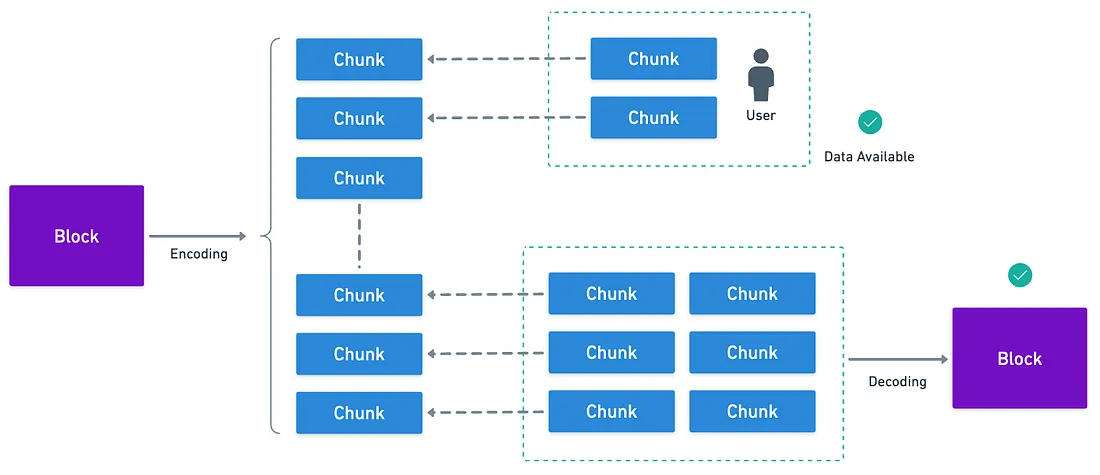
For this, they chose a technique called 2D Reed-Solomon encoding.
It’s a modification of a method we’ve already explored in the Cryptography 101 series, so you can read that for reference! And for the full rabbit hole experience, here’s the actual paper.
To give you a rough idea of how this works, Celestia takes all transaction data in a block, and arranges it into a square matrix — let’s say it’s in size. Then, they apply the encoding technique (Reed-Solomon) to expand this into a matrix, adding redundancy both horizontally and vertically.
Then, they do something really clever: instead of calculating a single Merkle root for the block’s transactions, a Merkle root is calculated for each row and each column of this matrix. And with it, they create a master Merkle root that combines all these individual roots.
What for, you ask? Well, say you want to verify the data for some block is available, without querying the full block. You can randomly pick positions in this expanded matrix, (say and ). You request these chunks of the encoding, and also ask for valid Merkle proofs for those positions.
Of course, you’ll receive a proof for the row and column of each of your chosen points, and then a proof for the full expanded block.
Since constructing any of these proofs is extremely hard without knowledge of the original data, then we can say with very high probability that the data is known and available by whoever creates these proofs.
Just by sampling a few points!

It’s hard to come up with a good analogy, but it’s kinda like asking someone to prove they have a completed — piece jigsaw puzzle without showing you the whole thing.
You randomly ask to see a few specific pieces — maybe the piece that should be at position and another at . If they can show you those exact pieces, and somehow prove they fit perfectly with the surrounding pieces around them, you can be confident they actually have the complete puzzle.
Block Contents
Lastly, we’ll want to look at what actually lives in a Celestia block.
As we know, the goal here is not to execute Smart Contract logic. This means transactions don’t describe complex state transition functions.
But then... What do we store? Or to say it differently, what do transactions look like in Celestia?
Well, it’s a Data Availability Layer we’re talking about. So what we want to make available in blocks is data. Arbitrary chunks of data submitted by consuming applications, called blobs.
When, say, a rollup wants to use Celestia, it packages its transaction data into these blobs and submits them with a PayForBlobs transaction. Blobs are also organized into namespaces, where they get an identifier so different rollups can find their own data, and ignore everything else.
In sum, a Celestia block will contain:
- Transactions — mainly
PayForBlobstransactions, although there are other transaction types, - Blob data from various rollups or applications using Celestia,
- Some other metadata.
Notice that the Merkle proofs that tie it all together are not part of the blocks though, and are generated on demand.
Impact
It’s a good moment to remind ourselves how we arrived at Celestia in the first place.
All this technical complexity serves a simple but powerful purpose: making it possible for anyone to verify blockchain data without spending a bunch of money on expensive hardware, or consuming massive bandwidth.
Think about what this means for a moment. Recall that traditionally, if you want to truly verify what’s happening on a Blockchain (rather than just trusting someone else), you need to run a full node. That means:
- Downloading hundreds of gigabytes
- Maintaining constant internet connectivity
- Having enough computing power to process every transaction.
Data Availability Sampling enables a user with a smartphone to randomly sample a few pieces of data and get nearly the same security guarantees as someone running a full node.
Thus, anyone can run these so-called light nodes or clients, and actively participate in the verification process!
The real breakthrough is transforming Blockchain verification from an expensive privilege into something accessible to anyone. And importantly:
![]()
![]() The more people who can afford to verify, the more decentralized and trustworthy the system becomes.
The more people who can afford to verify, the more decentralized and trustworthy the system becomes.![]()
![]()
Interestingly, Celestia is not the only Blockchain doing this: as we already mentioned in previous articles, Polkadot (and JAM) handles DA in its own way and for its own purposes. Ethereum has also incorporated blobs not too long ago (Proto-danksharding), marking the beginning of their roadmap towards Danksharding, which has seen a major upgrade in the recent release of PeerDAS.
Summary
Blockchain was not originally conceived as the child prodigy of distributed databases. Sure, it solves things like immutability, censorship-resistance, and automatic execution really well, but massive distributed data storage was simply not in the books.
On a surface level, this might not sound as exciting as other Blockchain applications, but it’s one of the core challenges in their design. Every Blockchain architecture out there eventually runs into the same question: how do we handle more data without rendering the system unusable?
Crucially, not every piece of data needs the same treatment. We might be okay with storing things off-chain, but when stronger guarantees are required, Blockchain-native solutions might be best.
If anything, this article goes to show the spread and diversity of challenges to solve in Blockchain design. The many hurdles and obstacles have been overcome over the years, but new ones have popped along the way.
However, this only seems to fuel the community further, which keeps coming up with clever ideas and new paradigms.
It’s really an amazing space. I genuinely enjoy it!
We’ve covered quite a lot in the series so far. I hope to have sparked your curiosity a tiny bit, so you can continue learning on your own about these fantastic technologies.
To close things off, I want to go back to what keeps being the center of it all in today’s Blockchain landscape: Ethereum.
I’ll meet you on the finish line!


Did you find this content useful?
Support Frank Mangone by sending a coffee. All proceeds go directly to the author.